Search
Databricks is a unified lakehouse platform that brings together data engineering, analytics, machine learning, and AI on a single, scalable foundation powered by Delta Lake and Apache Spark.
SurveySparrow’s integration automatically pushes survey responses straight into your Databricks tables. You can create smart conditional syncs to send only the responses you need. Import everything at once or apply date filters for ongoing syncs.
Your customer feedback now flows directly into the same lakehouse where your product, sales, and behavioral data already lives – instantly queryable, model-ready, and governed.
Some valuable use cases include:
In this article, we’ll walk you through connecting your SurveySparrow account to Databricks and setting up powerful response mappings from start to finish, specifically:
1. Inside your SurveySparrow account, click on the settings icon.
2. Scroll down the left panel in the settings page till you see the Apps and Integrations option, then click on it.
3. Search for the Databricks integration using the search box (or scrolling through the integrations), then click on the toggle when you see it.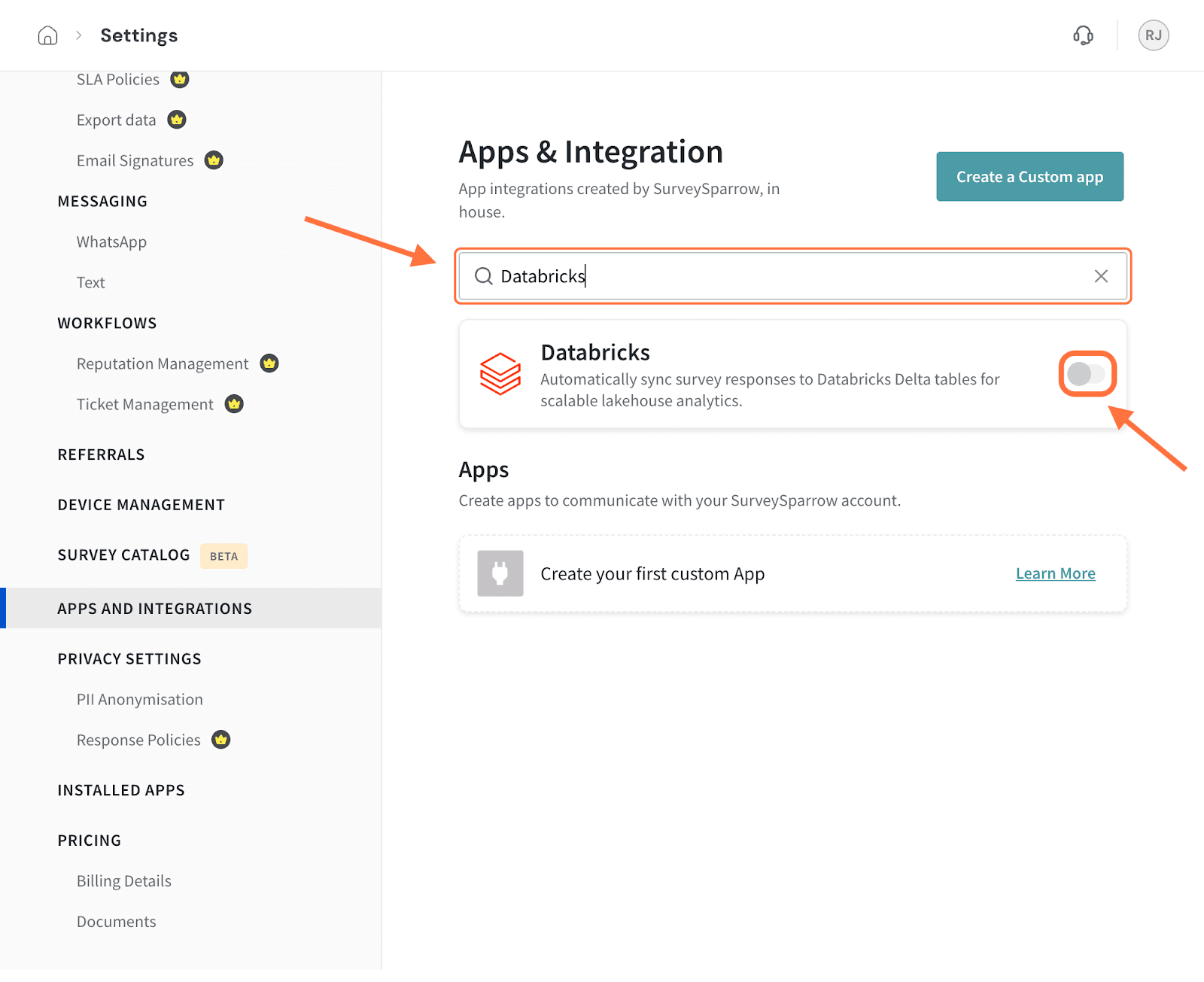
4. Next, in the setup screen you’ll need to enter your Databricks OAuth Client ID, Client Secret and Workspace URL.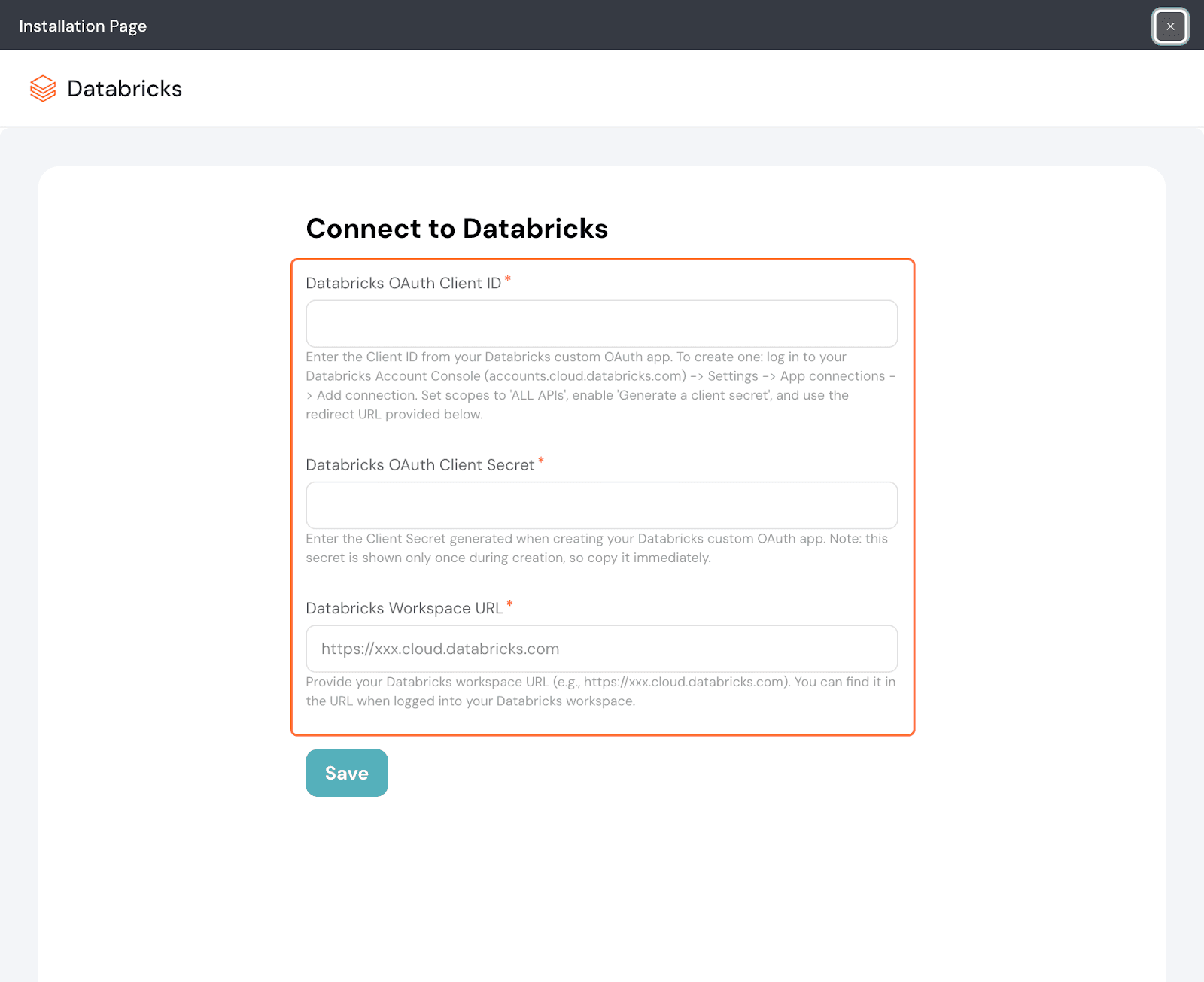
Note: To find these items, head to your Databricks account’s settings section. The App connections tab will be open by default. Click on Add connection.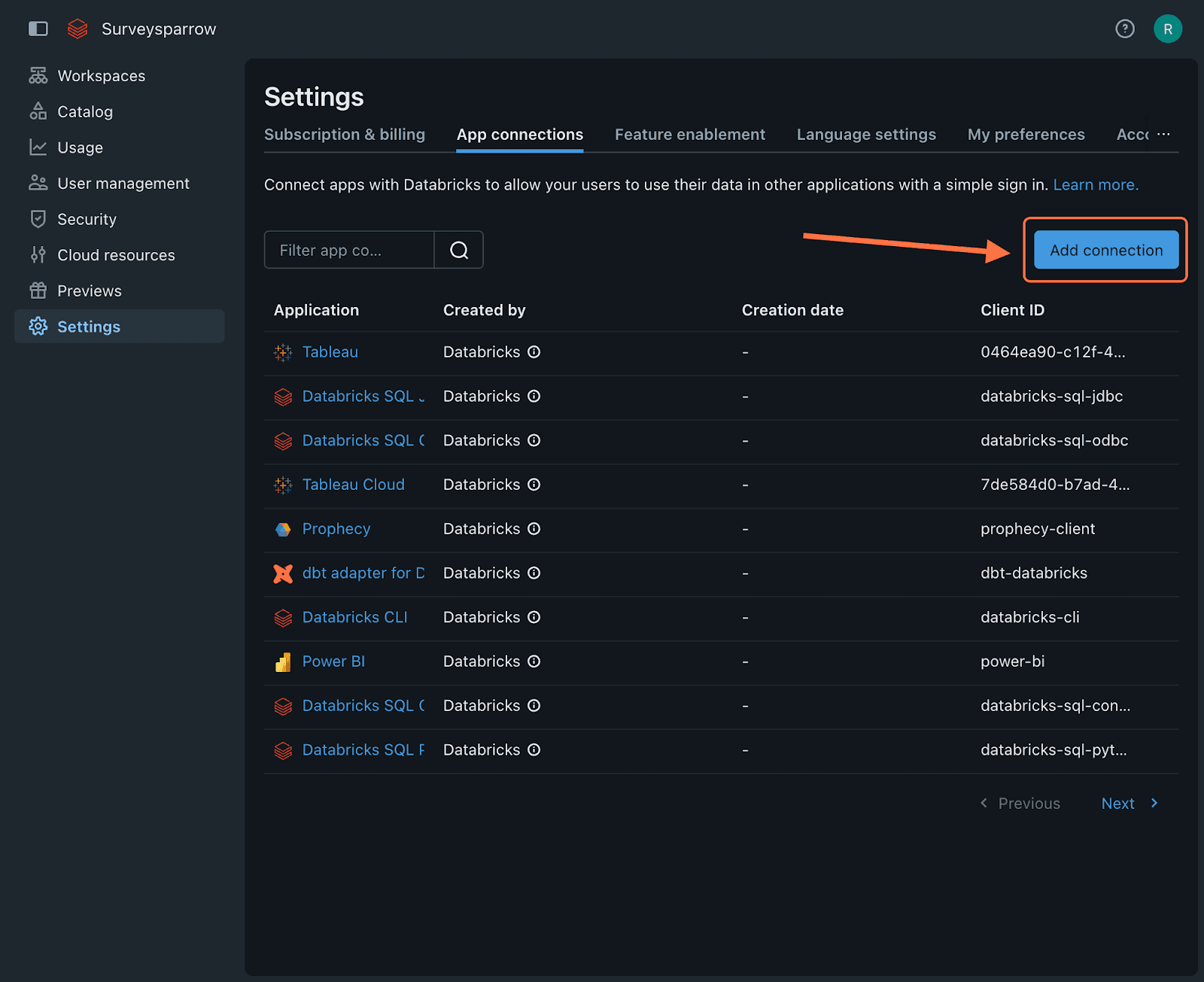
Type a name for the application and then paste the redirect URL for your account’s data center. Please refer to the list of URLs below to pick the right one for your data center.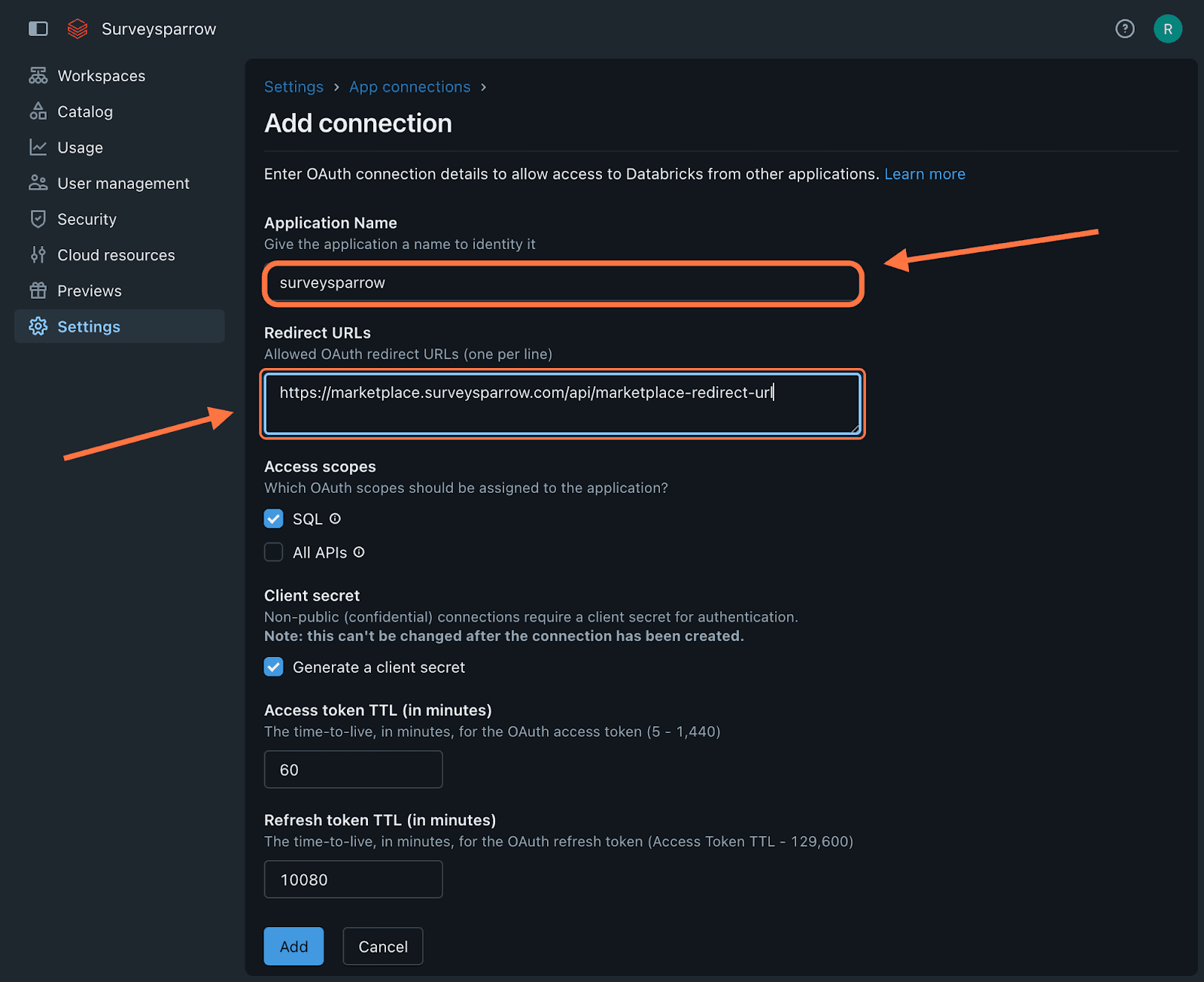
Click the checkbox for All APIs, then click on Add.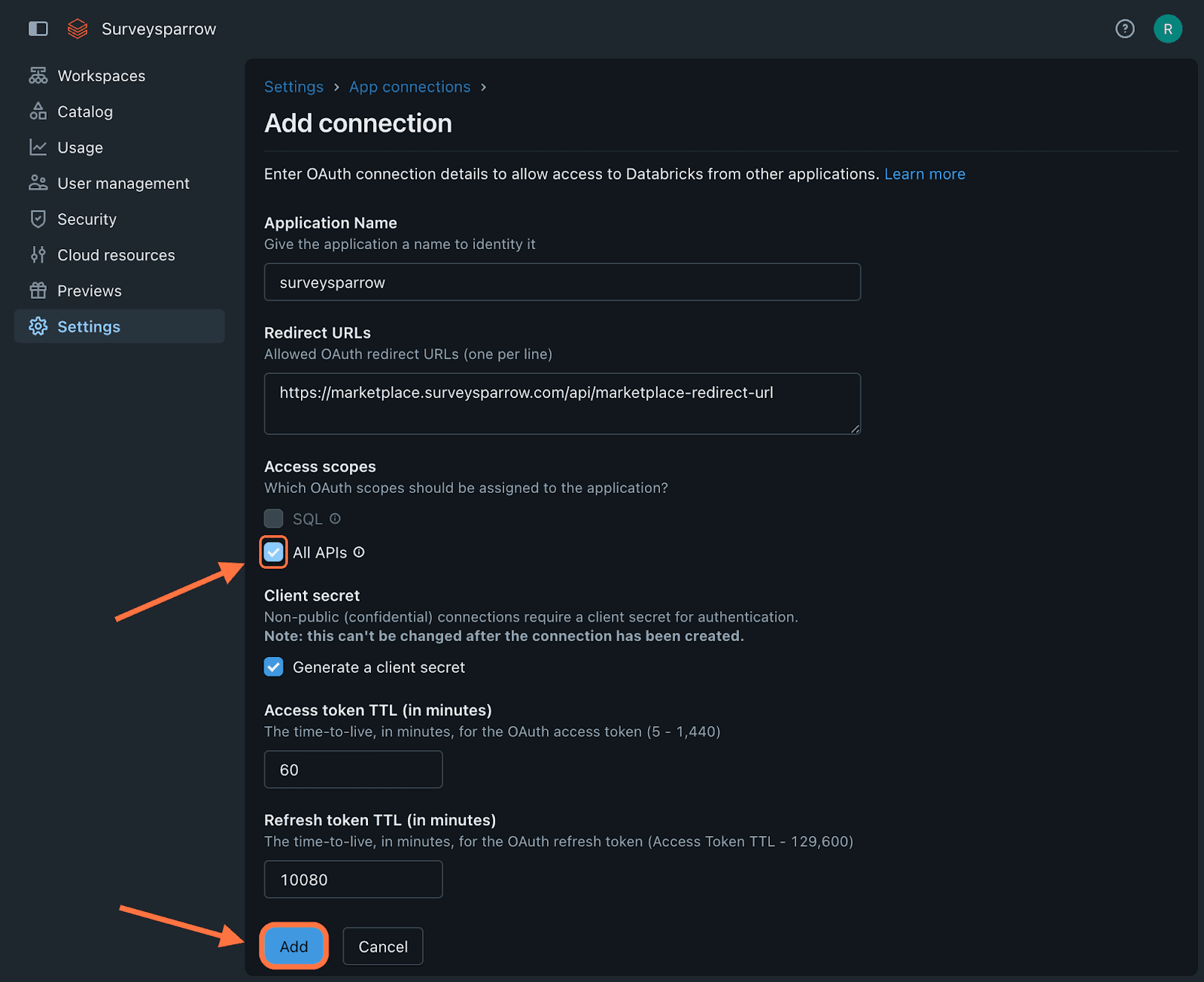
Once the connection is saved, you will see the Client ID and Client Secret in a new modal. Make sure to copy them and save them somewhere else before closing the modal. If you lose them, you will have to create a new app connection for the next time you try to sync responses to DataBricks.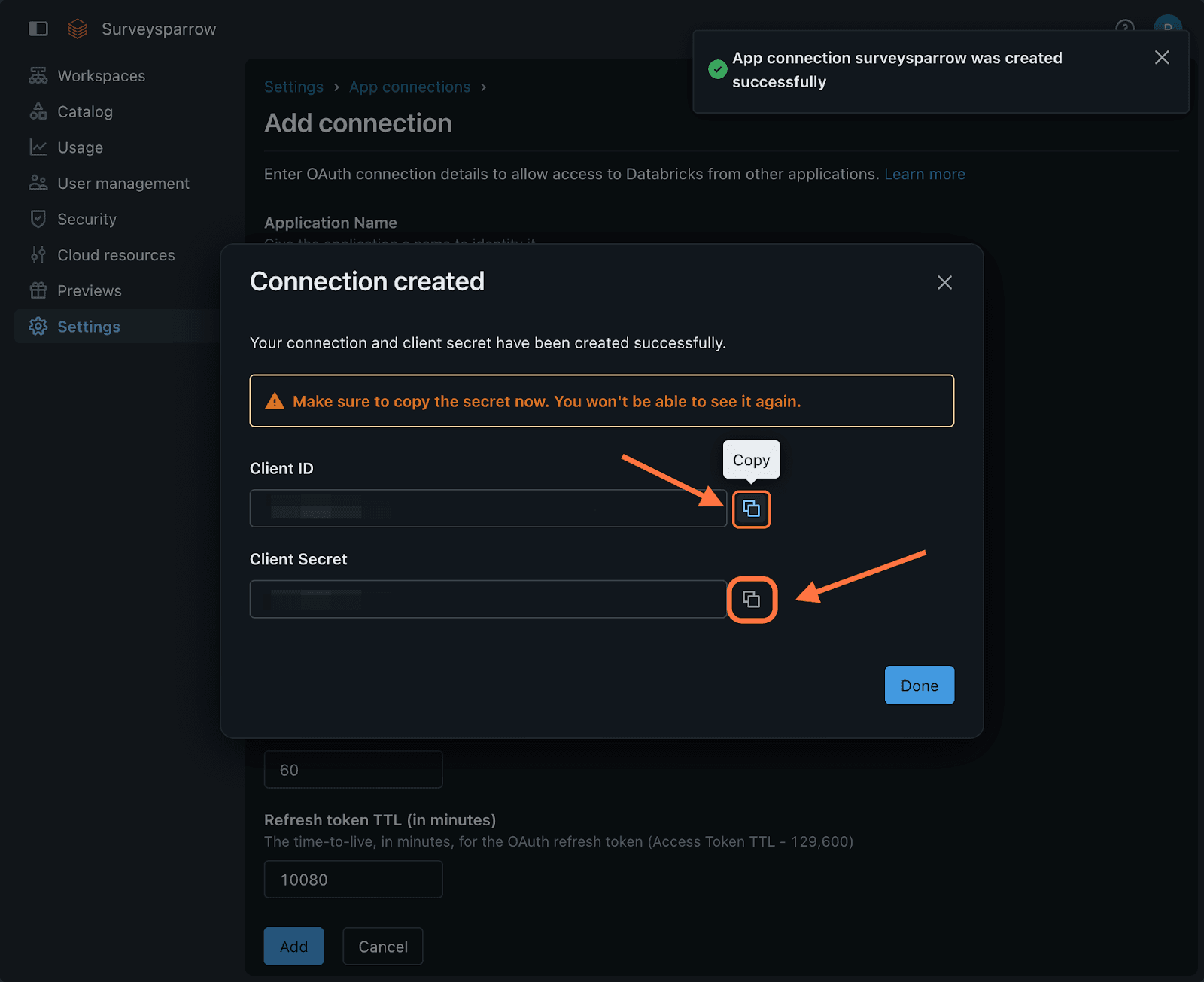
The workspace URL can be found in the address bar when you’ve opened DataBricks, up until databricks.com.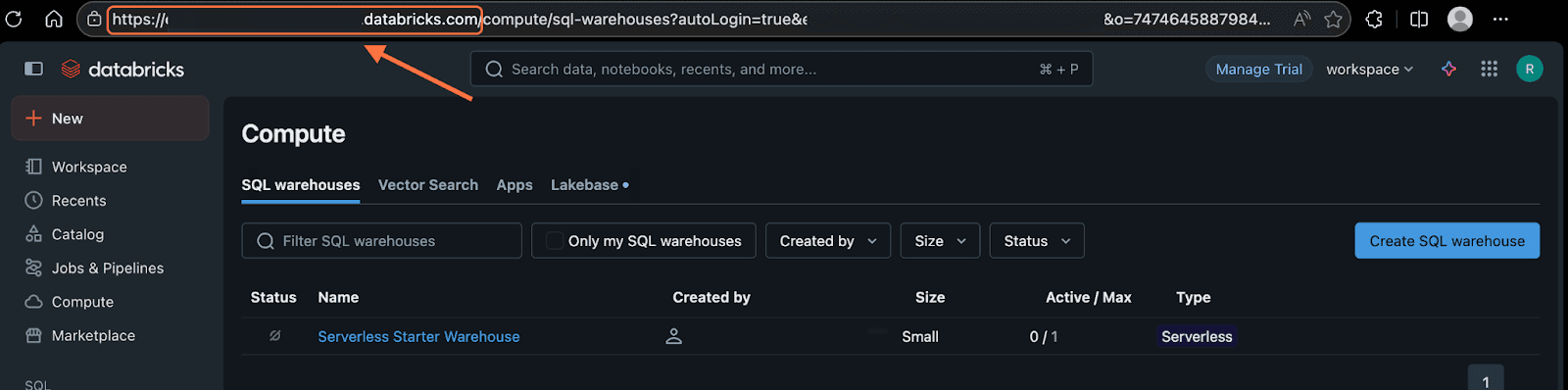
5. After entering the details back in SurveySparrow, click Save.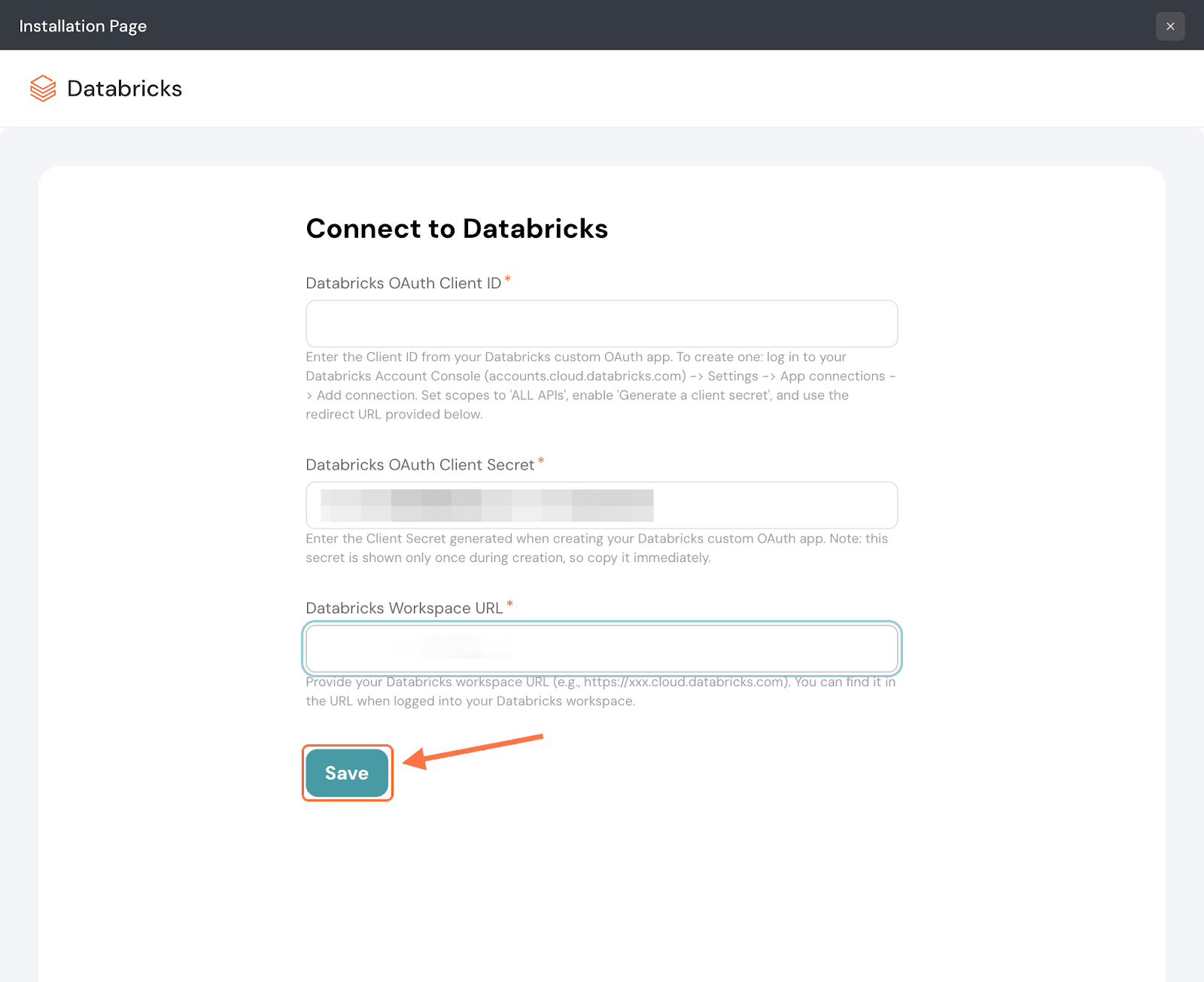
Note: Now the integration is live, but you need to make sure that your Databricks warehouse is running, so that responses can reach the tables within. To do this, inside the left panel of your Databricks account, click on Compute.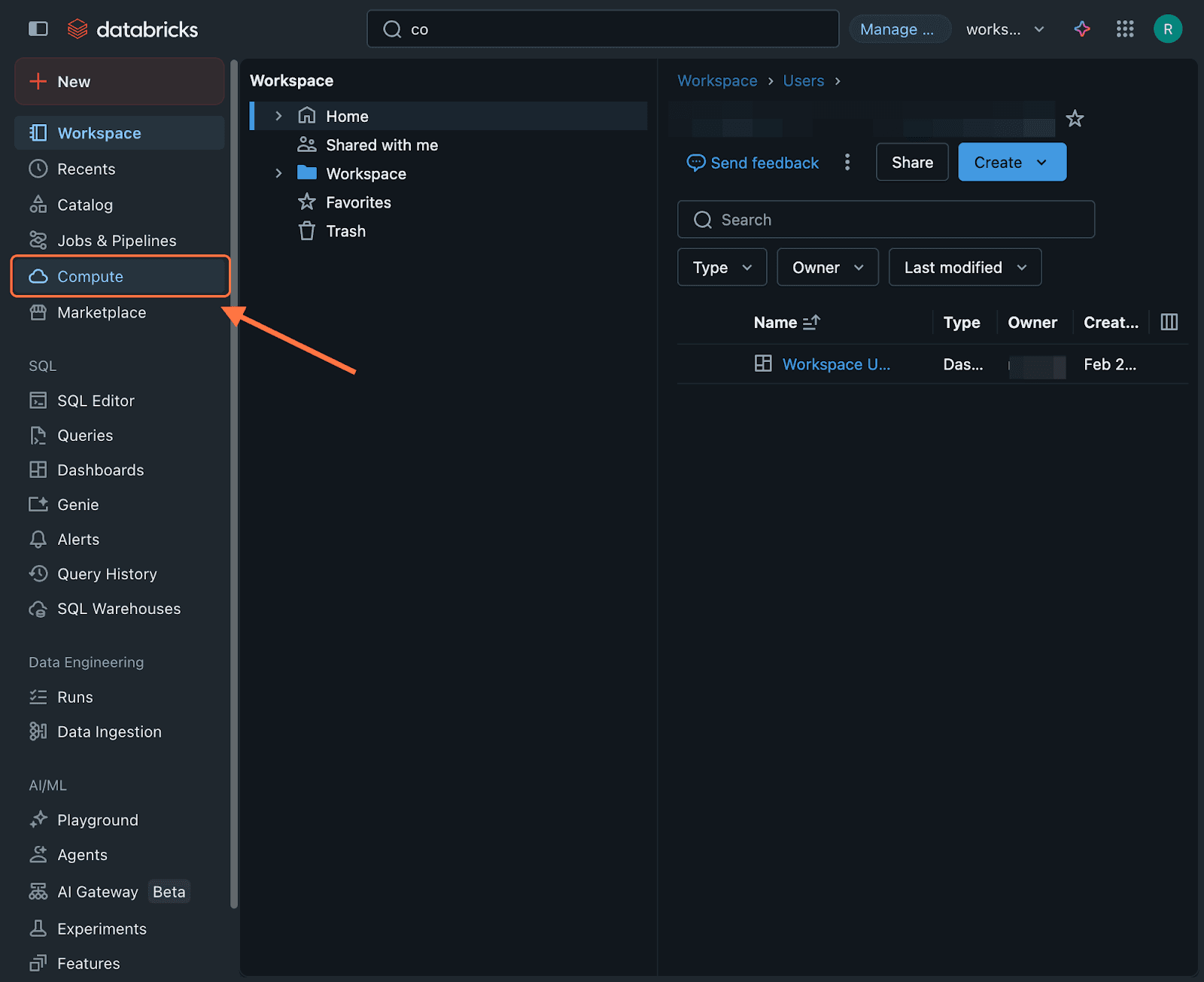
You will be taken to the SQL Warehouses section. When you see the warehouse to which you want the responses, inspect the icon under the Status column. If it shows a switched off icon, hover next to the three-dot icon on the right. A play button appears with a prompt to start the warehouse. Click on it. The Status icon will then show a green dot instead.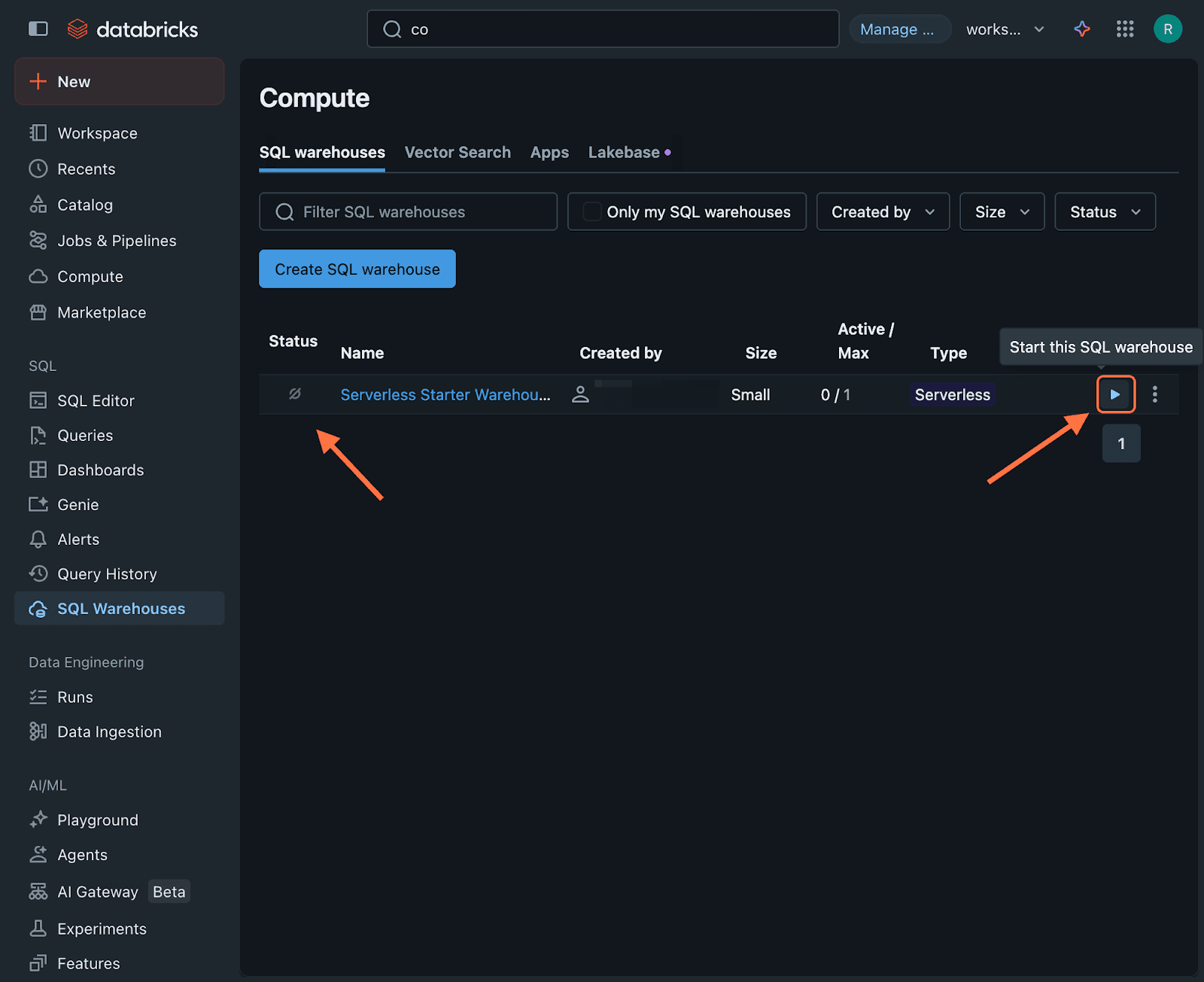
1. Open a survey and click on the Integrate/Configure tab.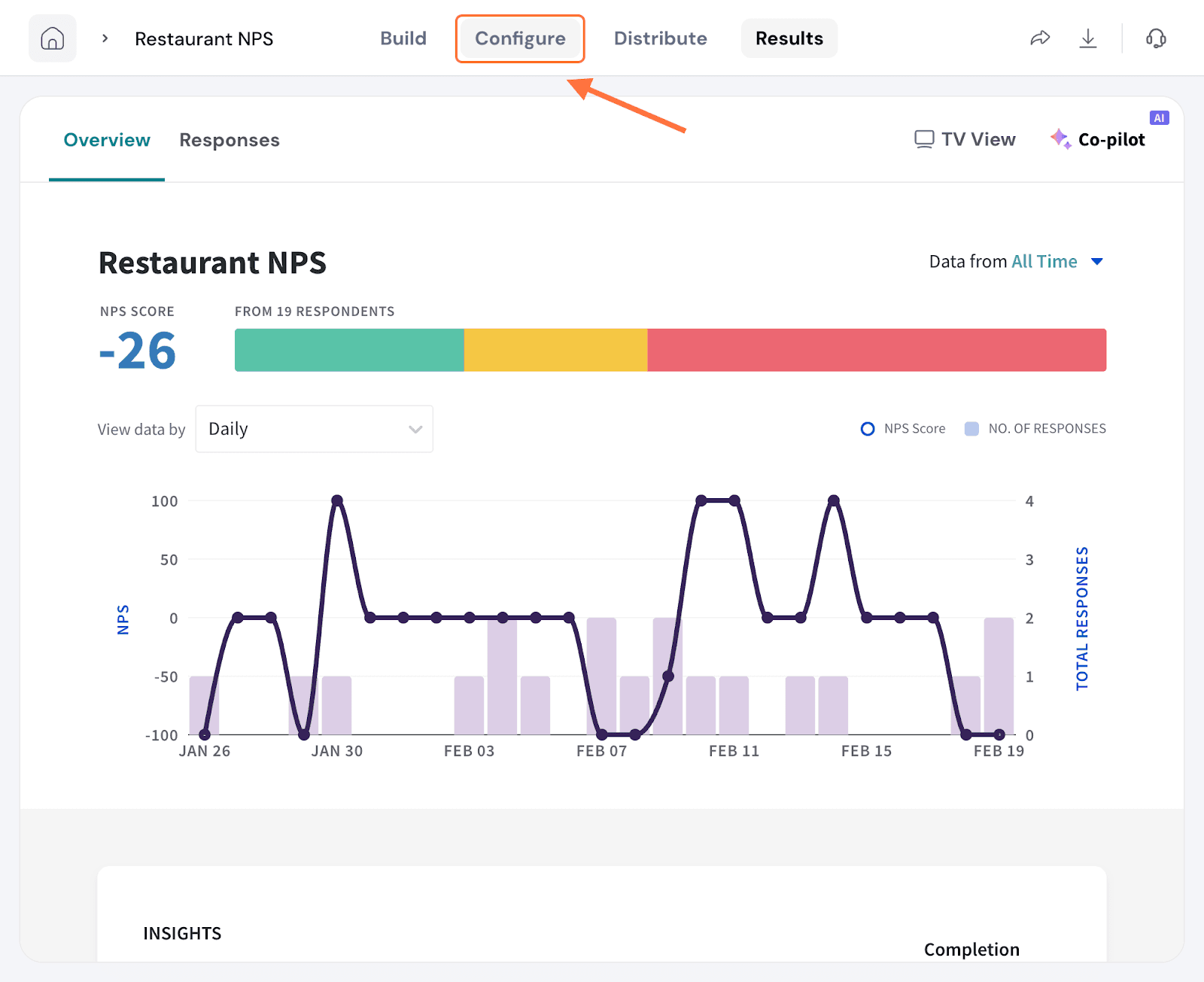
2. Search for the Databricks integration using the search box (or by scrolling through the integrations). When it appears, click on the toggle.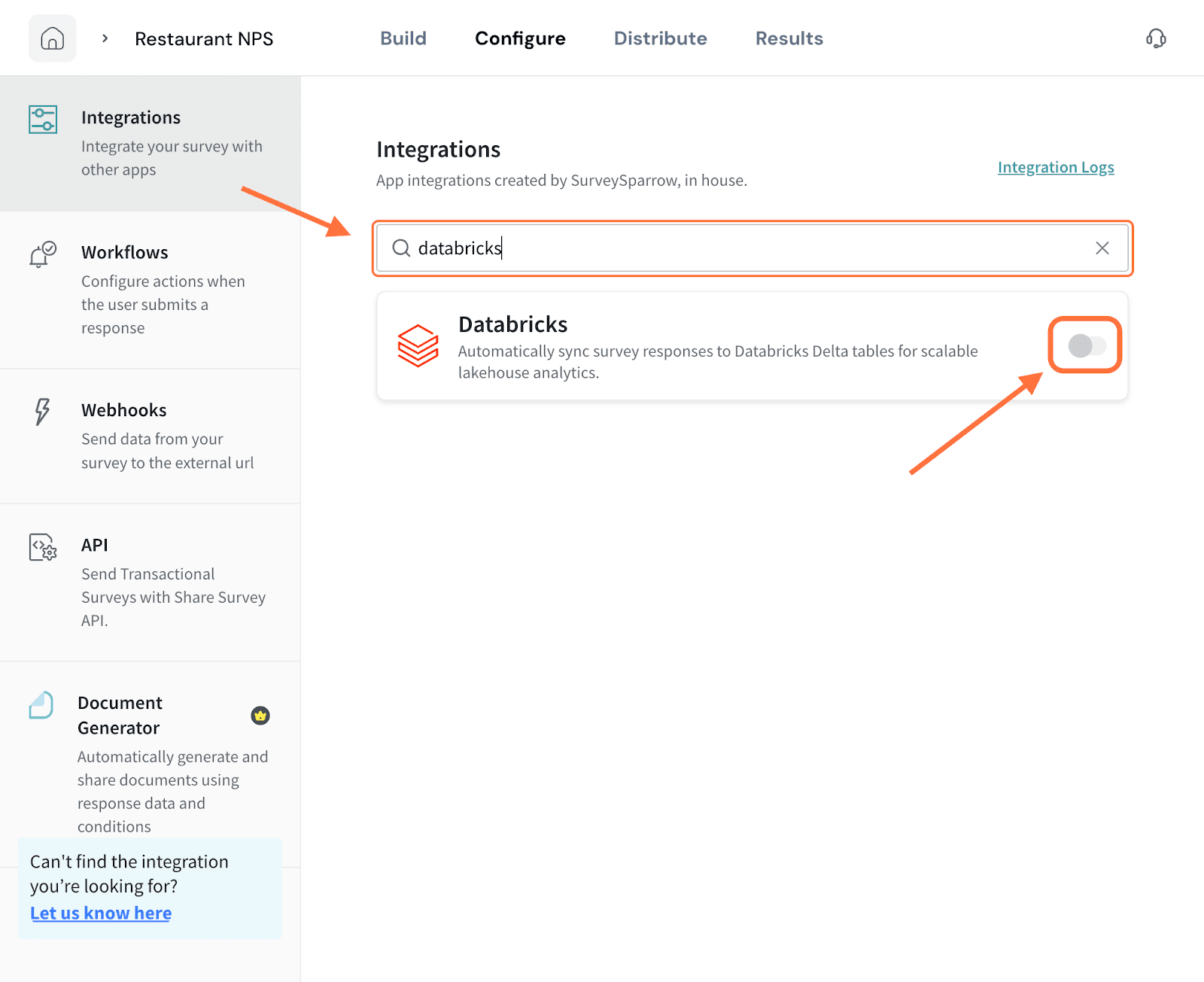
3. When the integration setup screen opens, you must first select the destination in Databricks where the data is to go. Start by selecting the warehouse. Click on the dropdown menu under SQL Warehouse and choose from the options.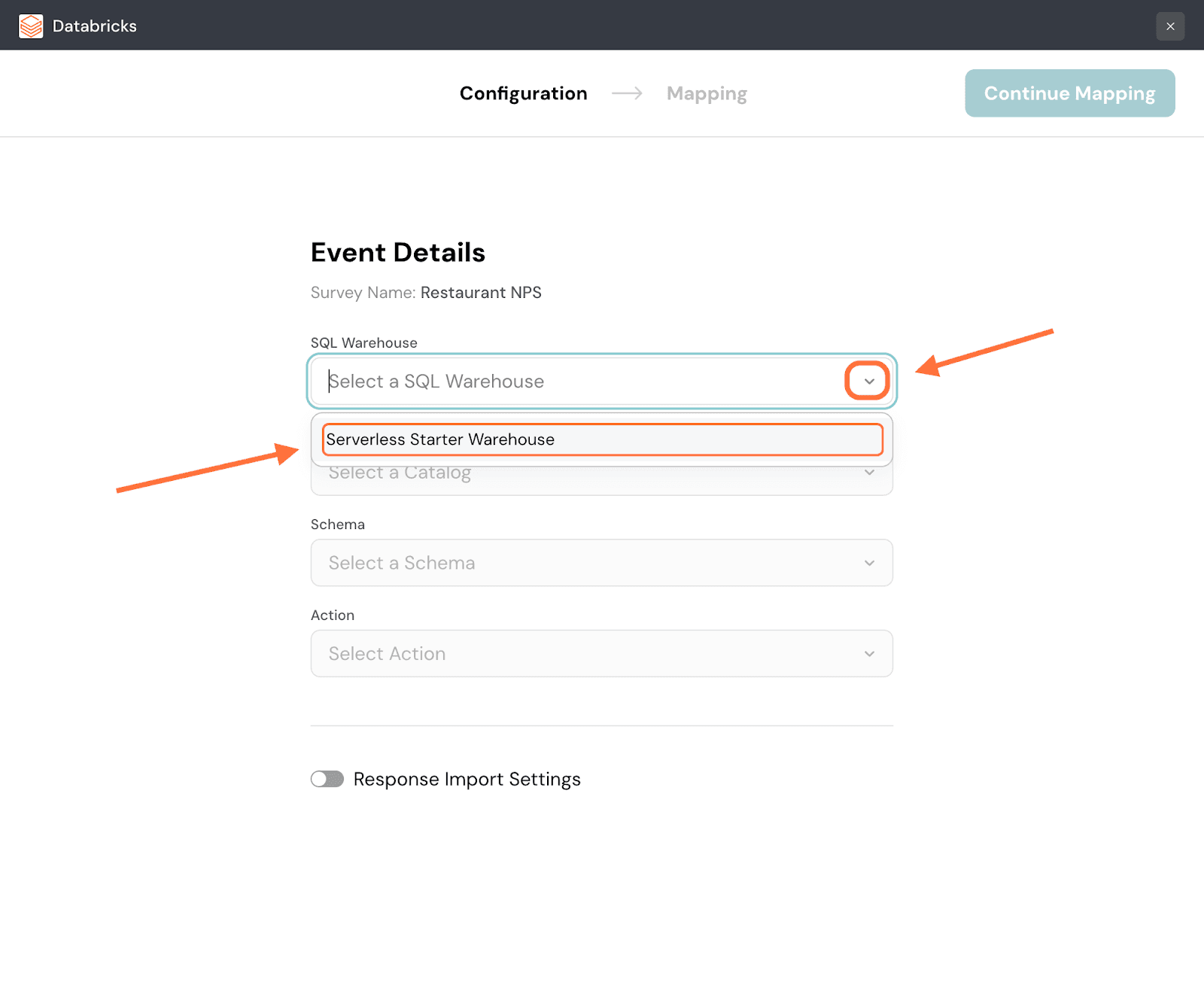
4. Next, you must select the Catalog to which you want to push the survey data. Click on the dropdown under Catalog and pick from the options.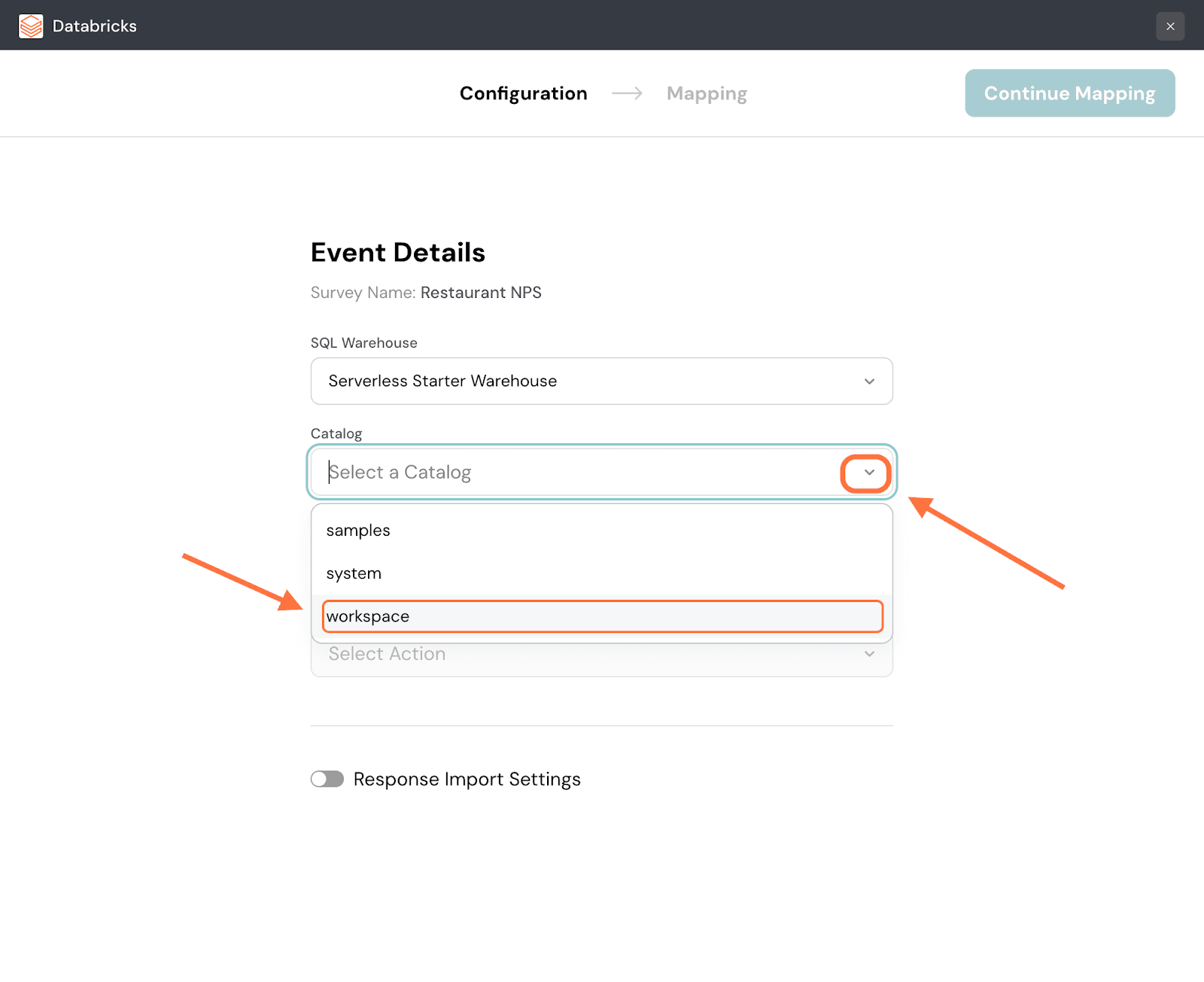
5. Click on the drop-down under Schema and choose from the options.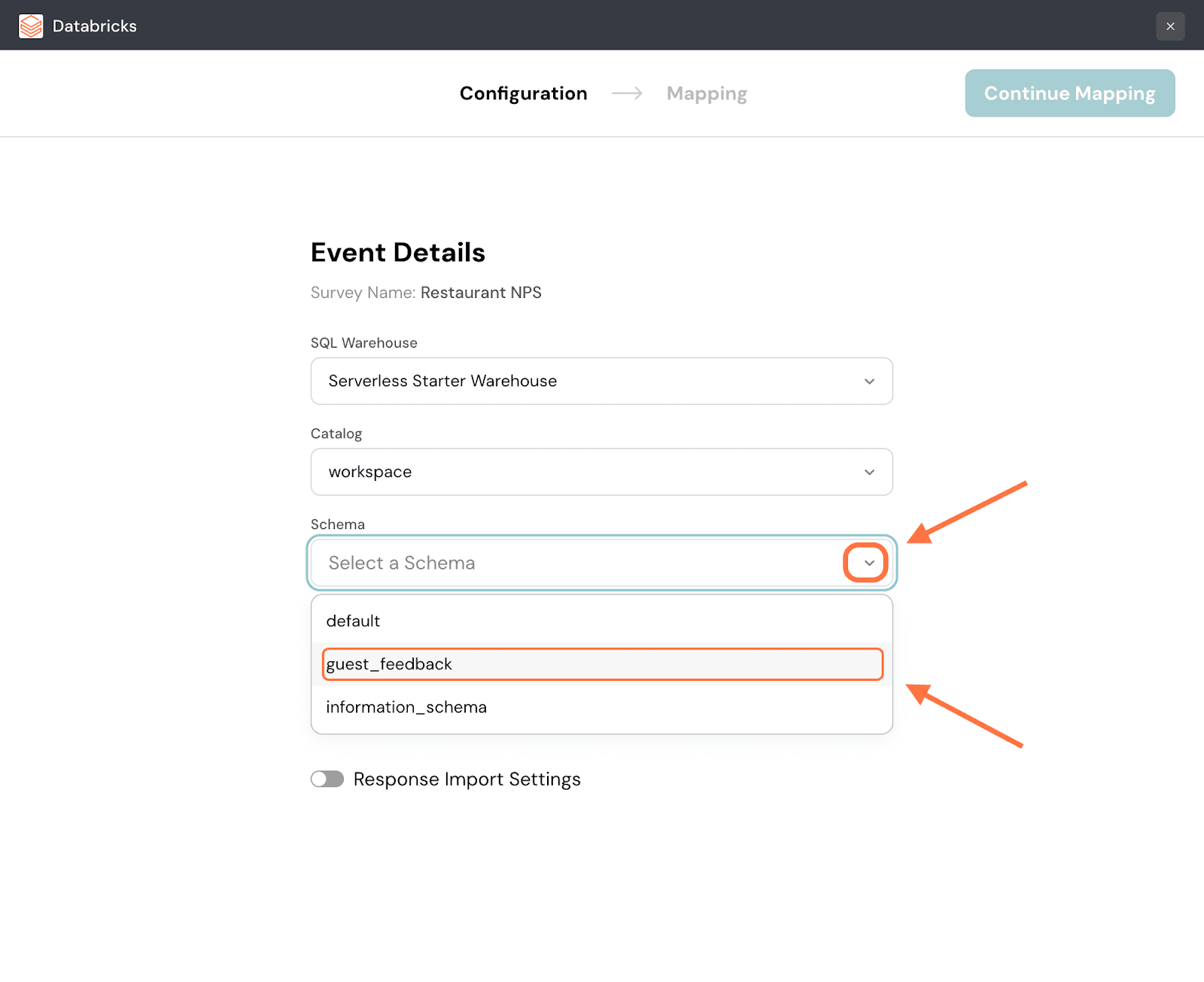
6. Now you must select the table to which you want to push the survey data. But you can either choose an existing table from the dataset or create a new one. Click on the dropdown under Action to decide. Both actions have different flows. We’ll first start with an existing table.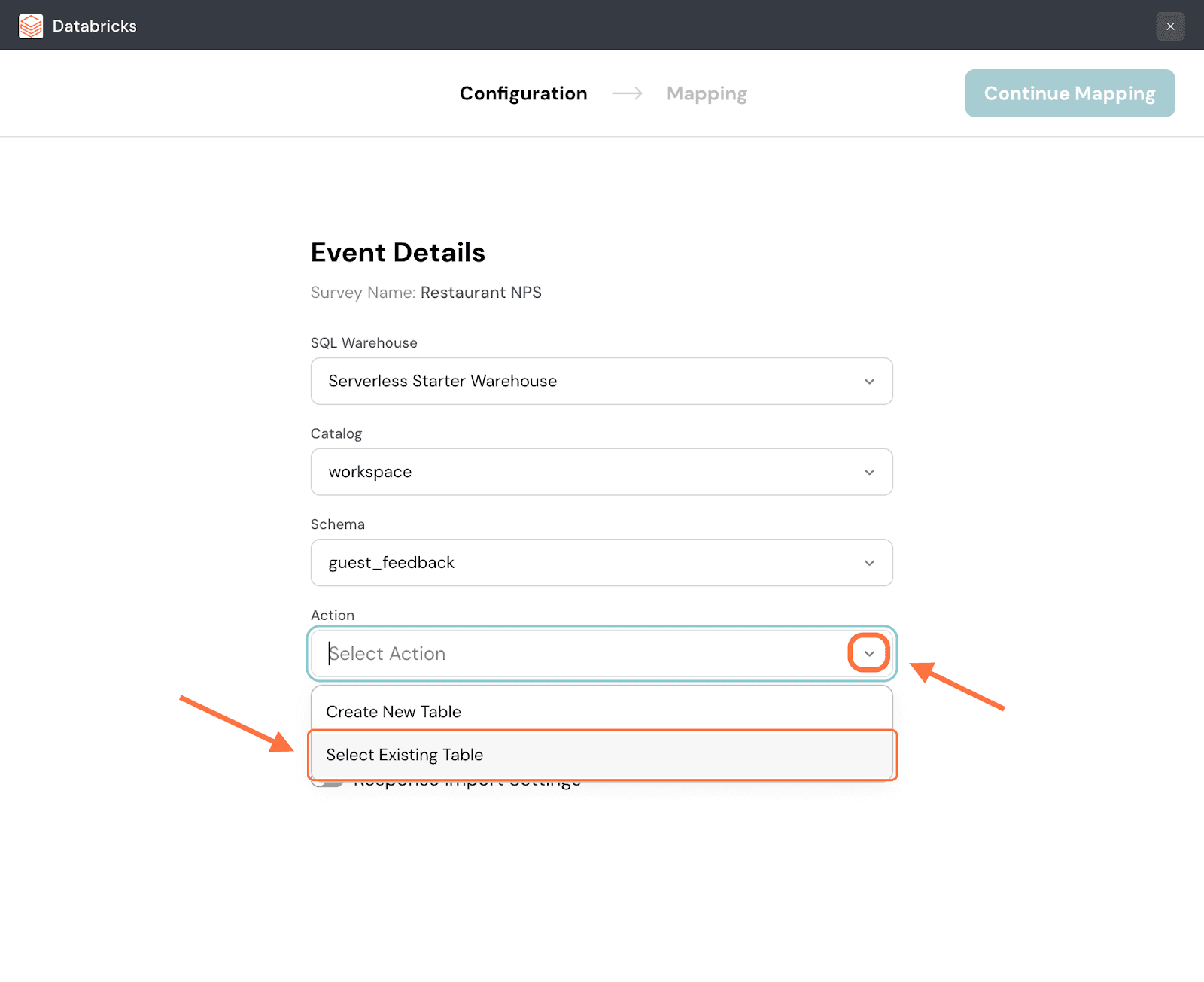
7. Next click on the drop-down button under Table and select from the options.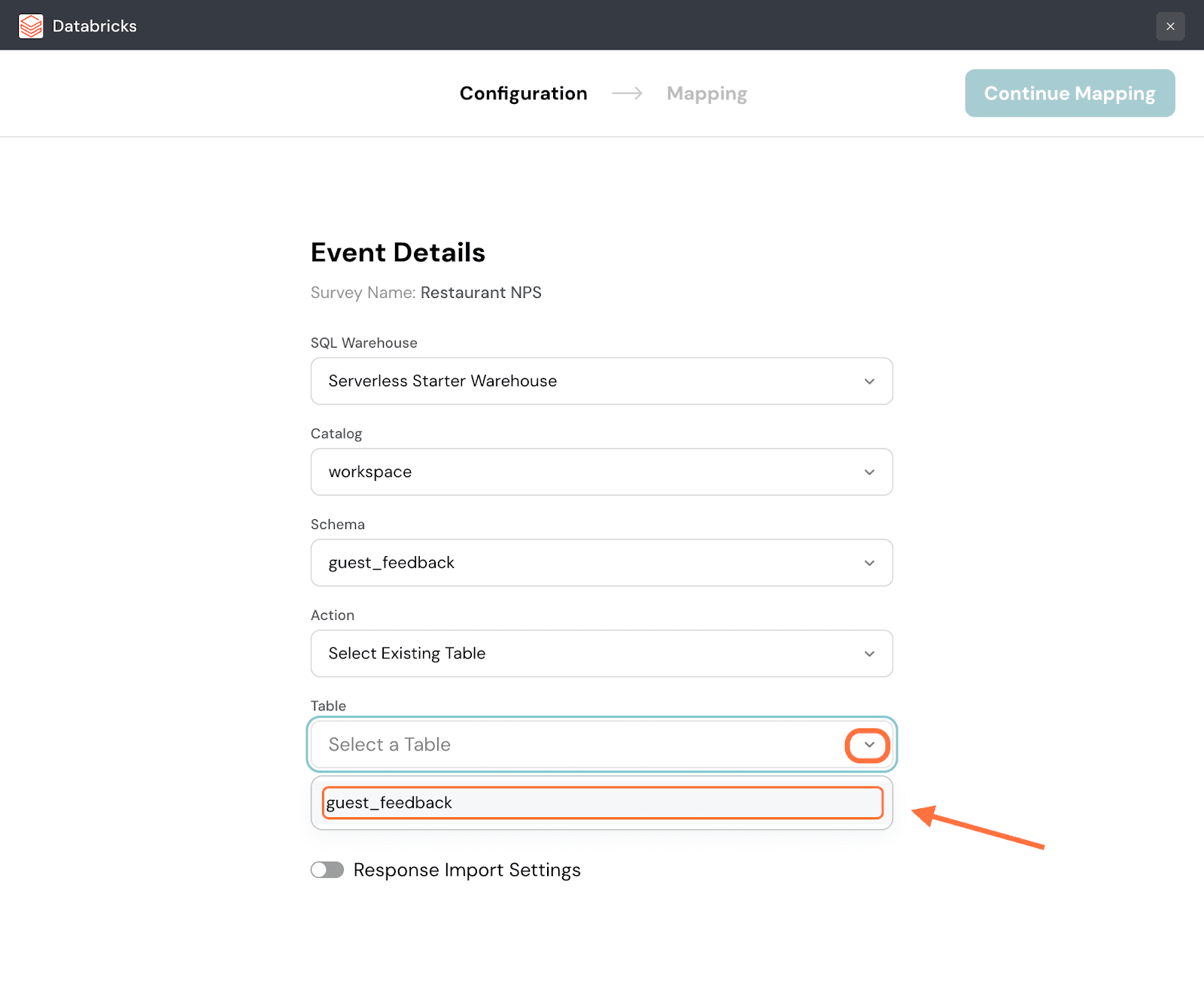
8. By default, only new responses are imported. If you want to only import responses from a specific date, click on the toggle next to Response Import Settings.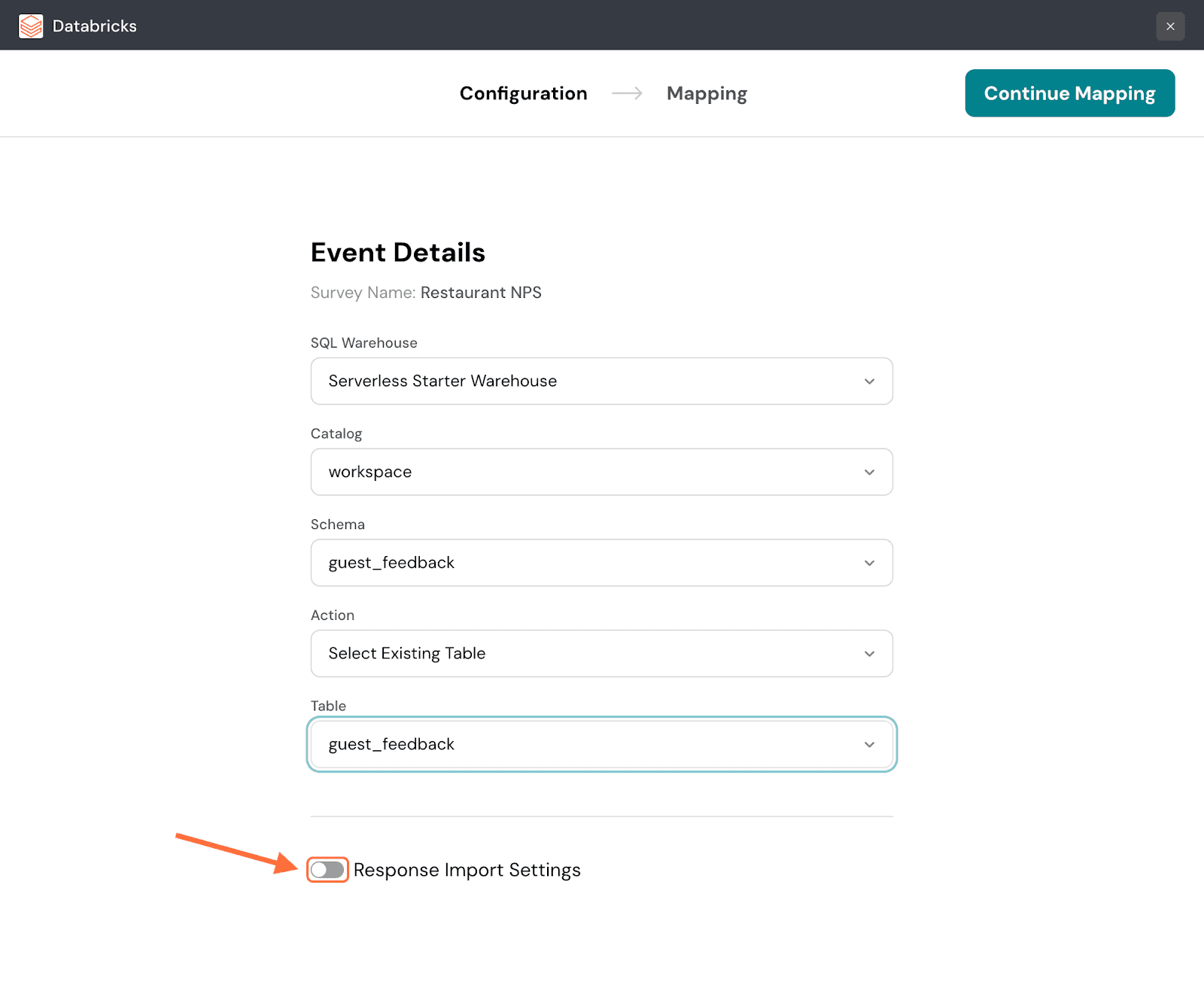
9. When you hover over the Specific Date option, a calendar will appear. Choose a date, then click on Apply.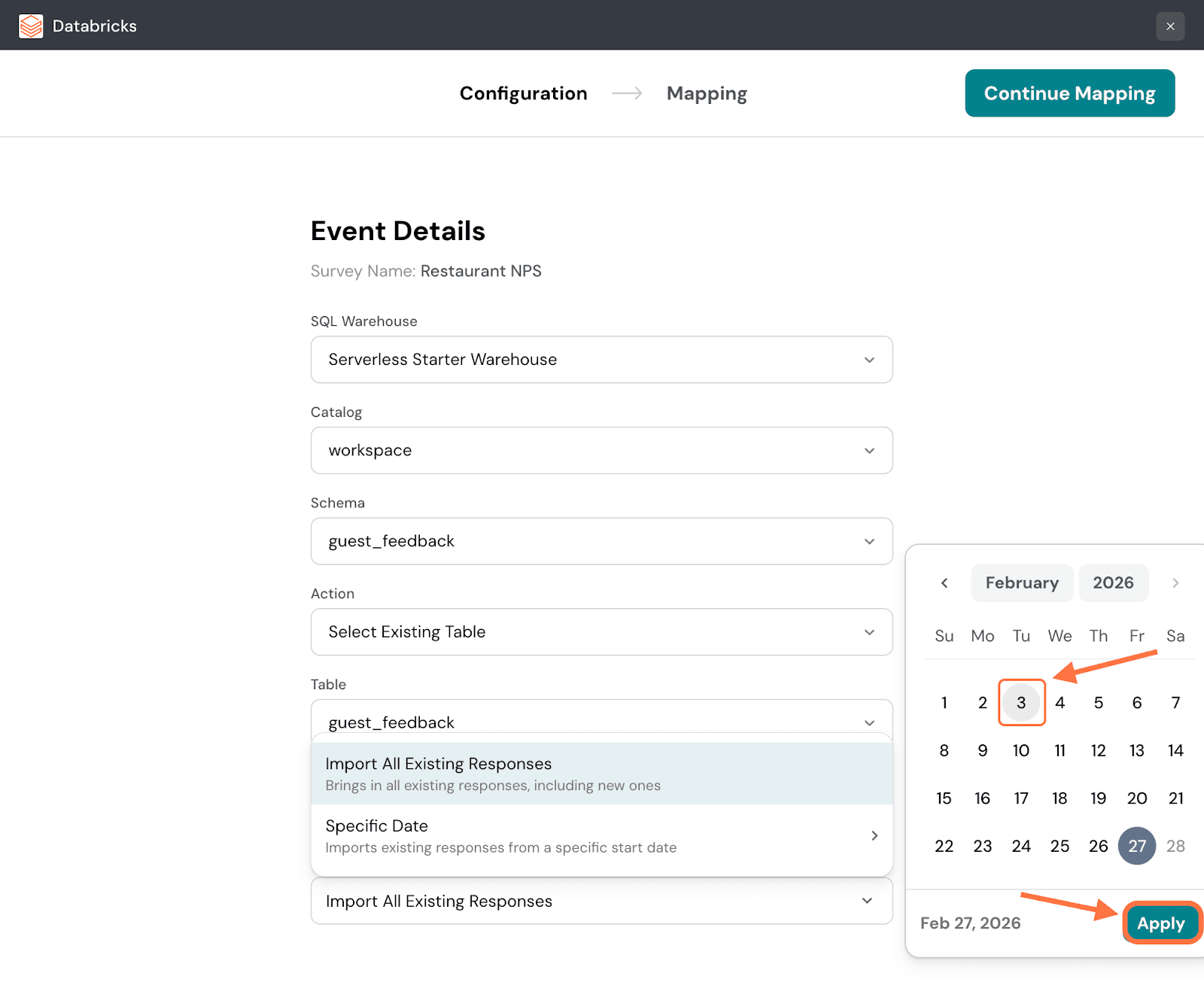
Note: You can also import all responses - existing and new, by clicking on the first menu option.
10. Click on Continue Mapping.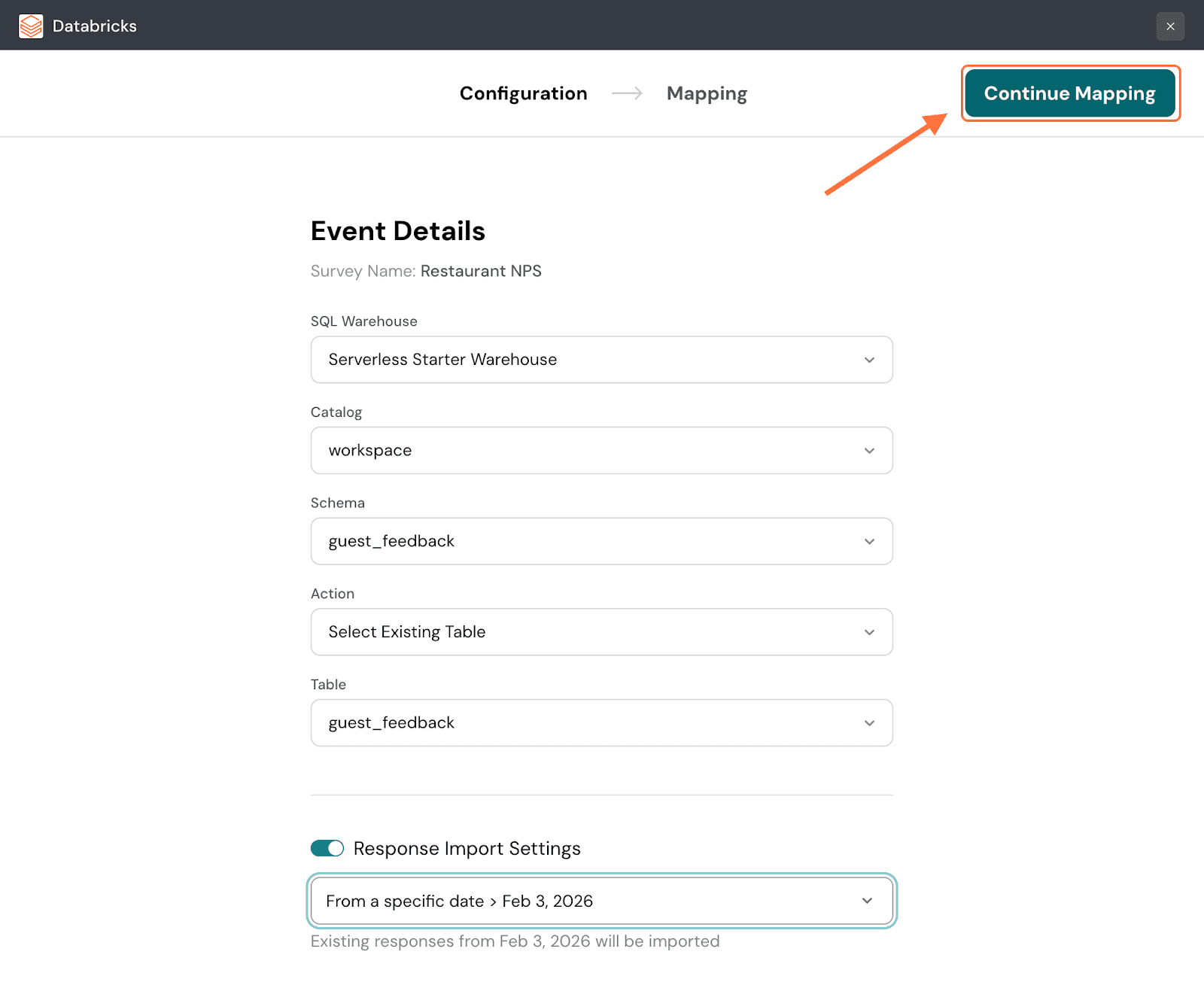
11. Now in the Mapping section, you need to configure which response properties are going to Databricks. First you can set conditions to decide which type of response gets synced to Databricks. Click on Set Conditions.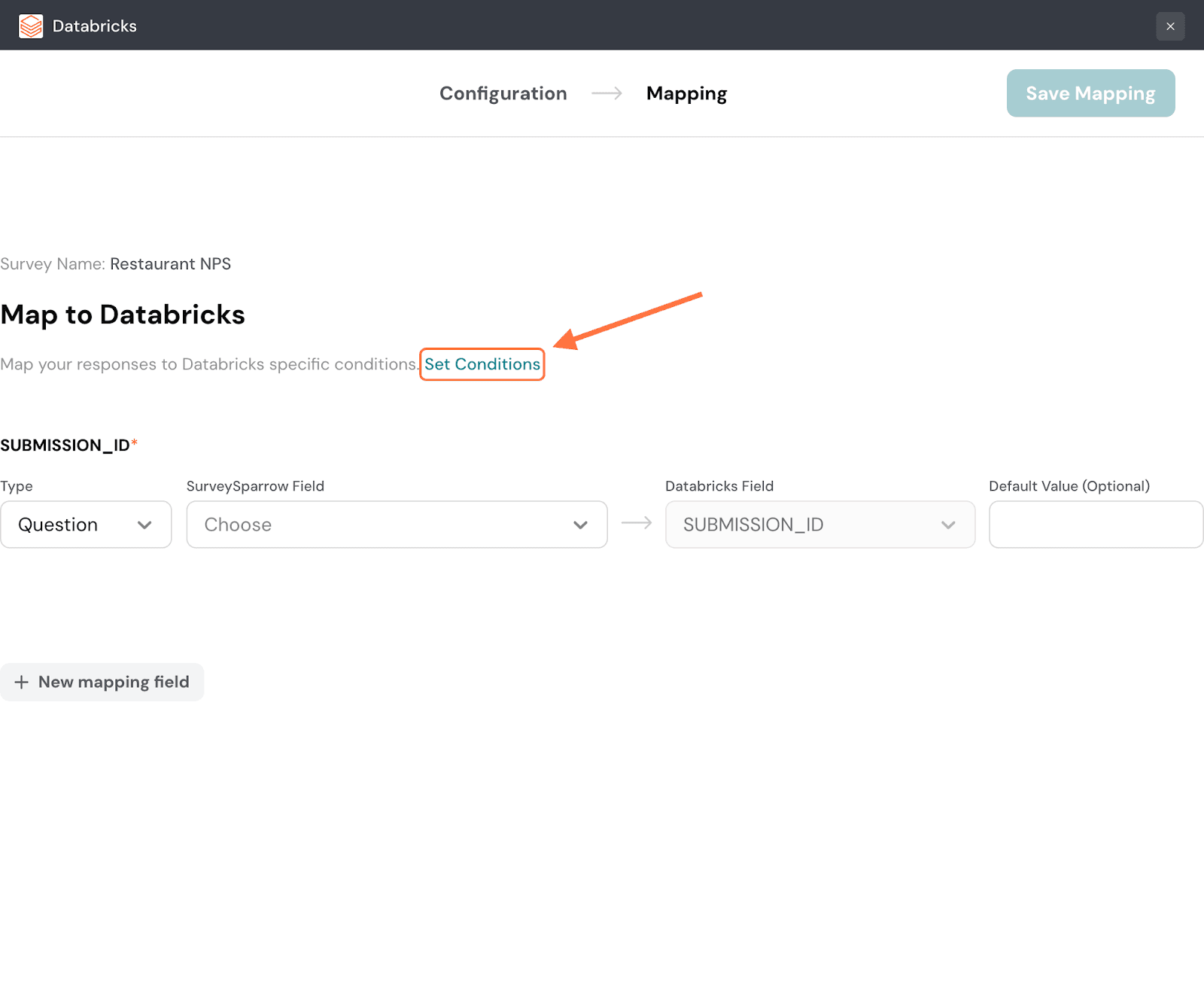
12. In the condition setting modal, you can set a conditional logic for the conditions: either any or all. The default setting is any, but if you’d like to change the logic, click on the drop-down next to it.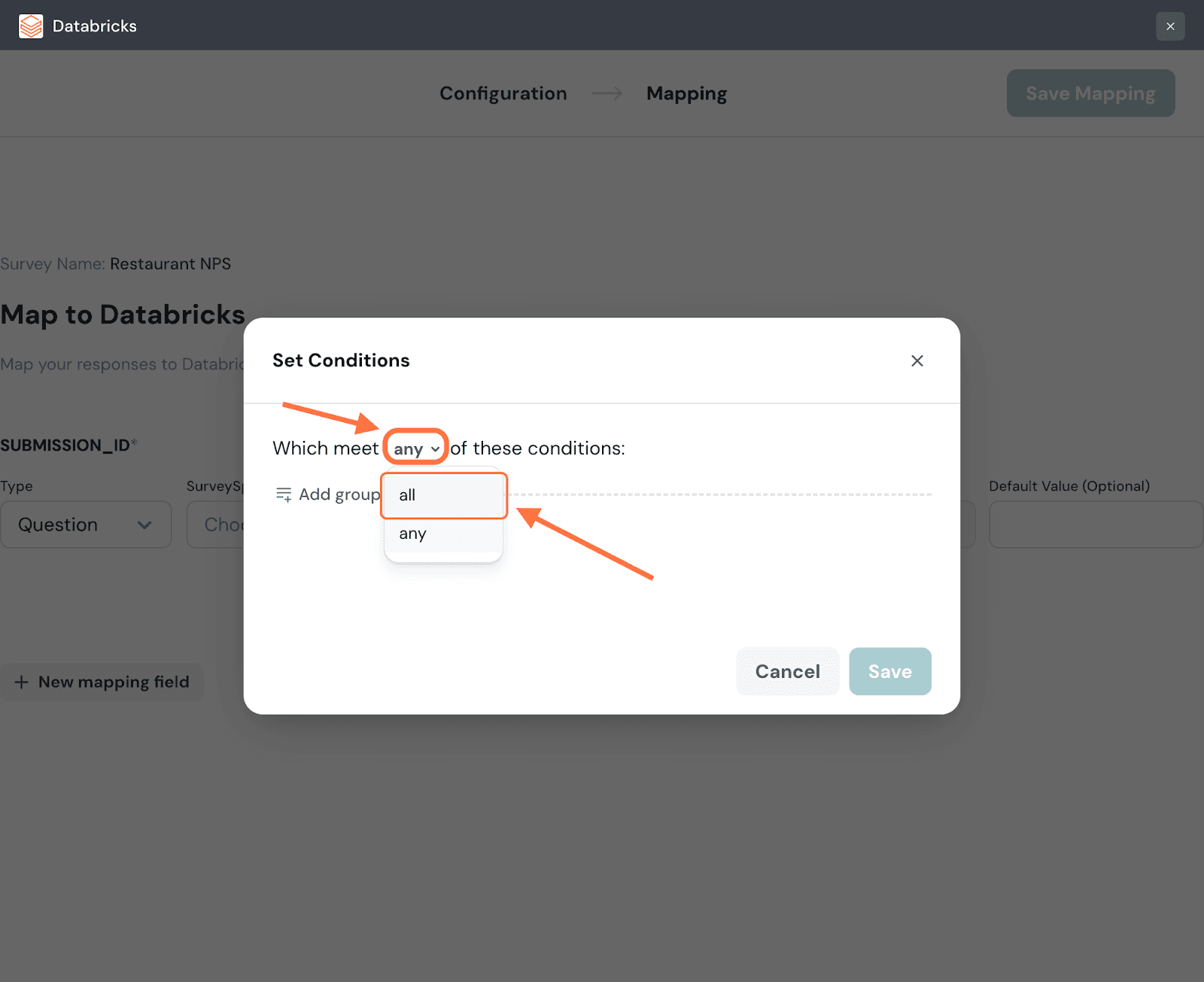
13. To add conditions, click on Add Group.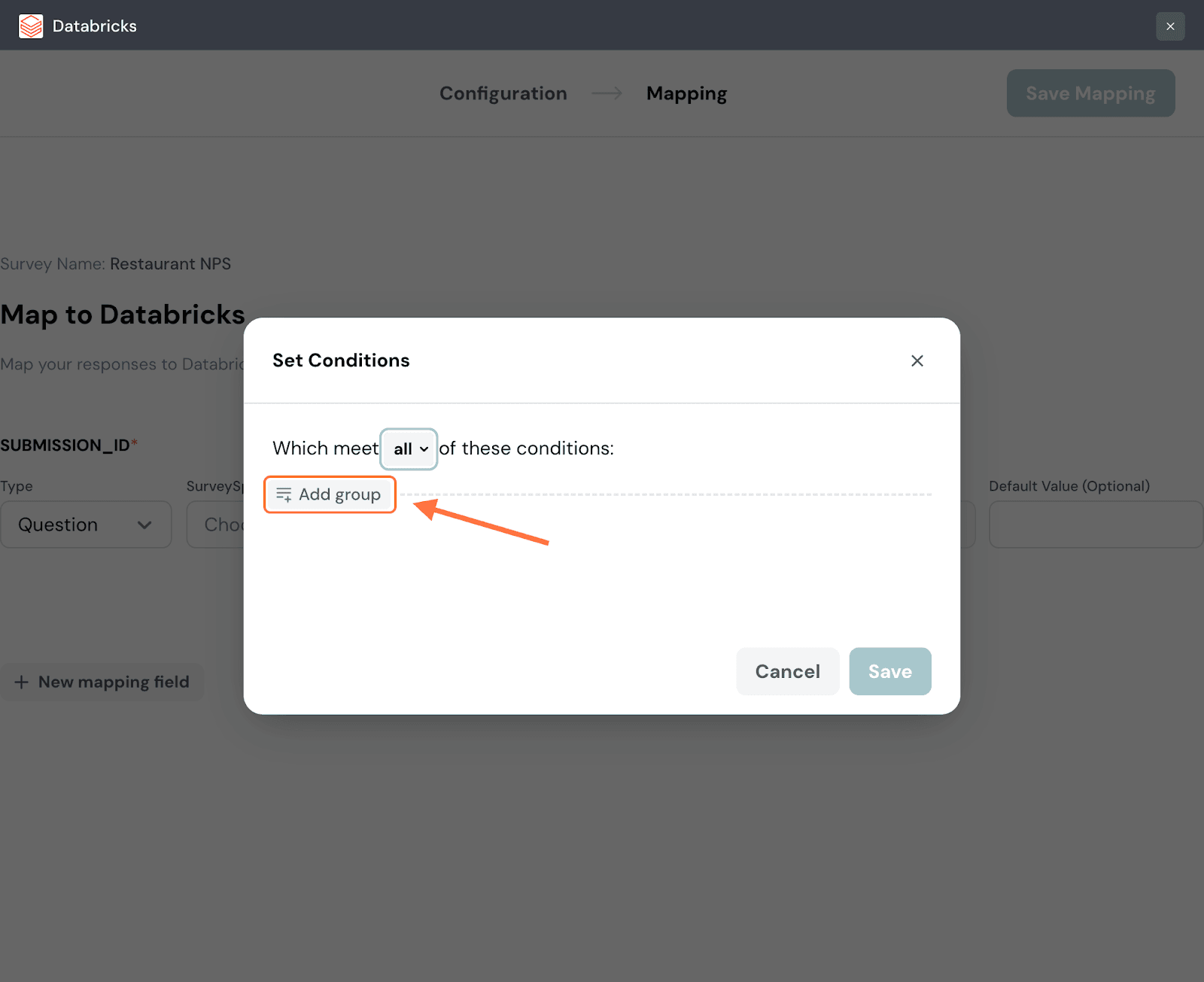
14. Choose a category of data from the drop-down menu to which the condition must apply. For this instance, let’s go with a question.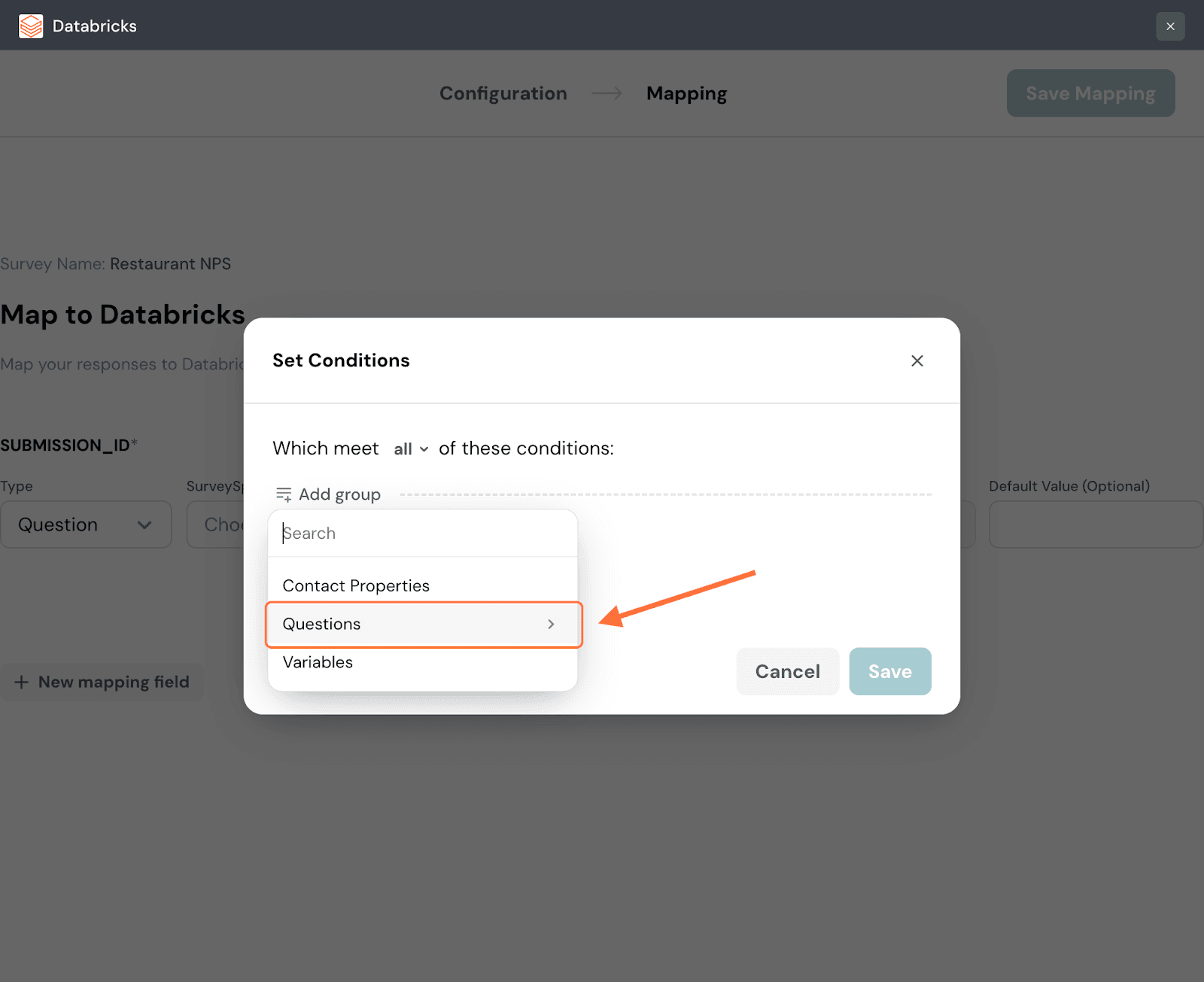
15. Choose a particular item from that category, in this instance a question.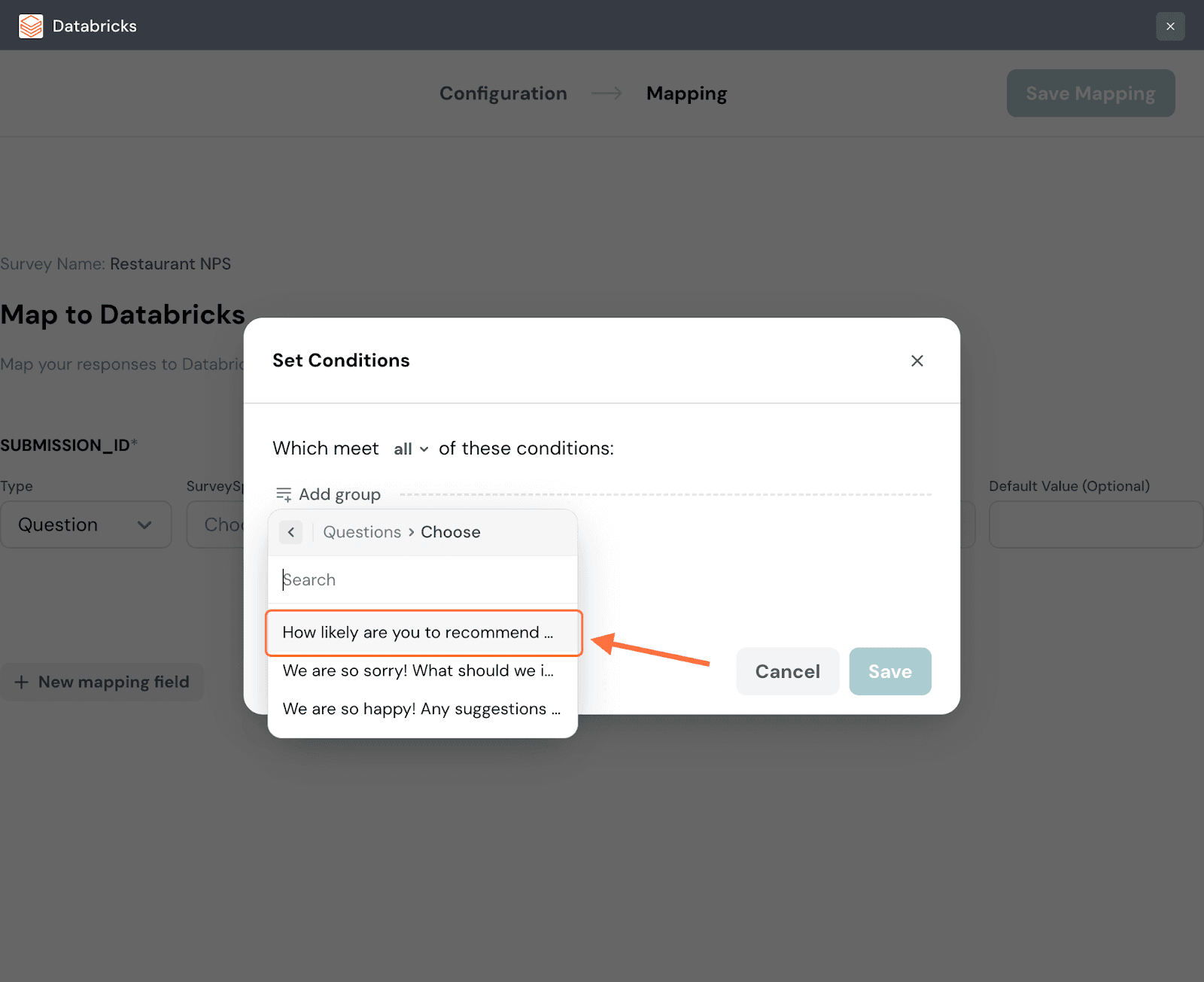
16. Click on Choose Condition to start defining the condition.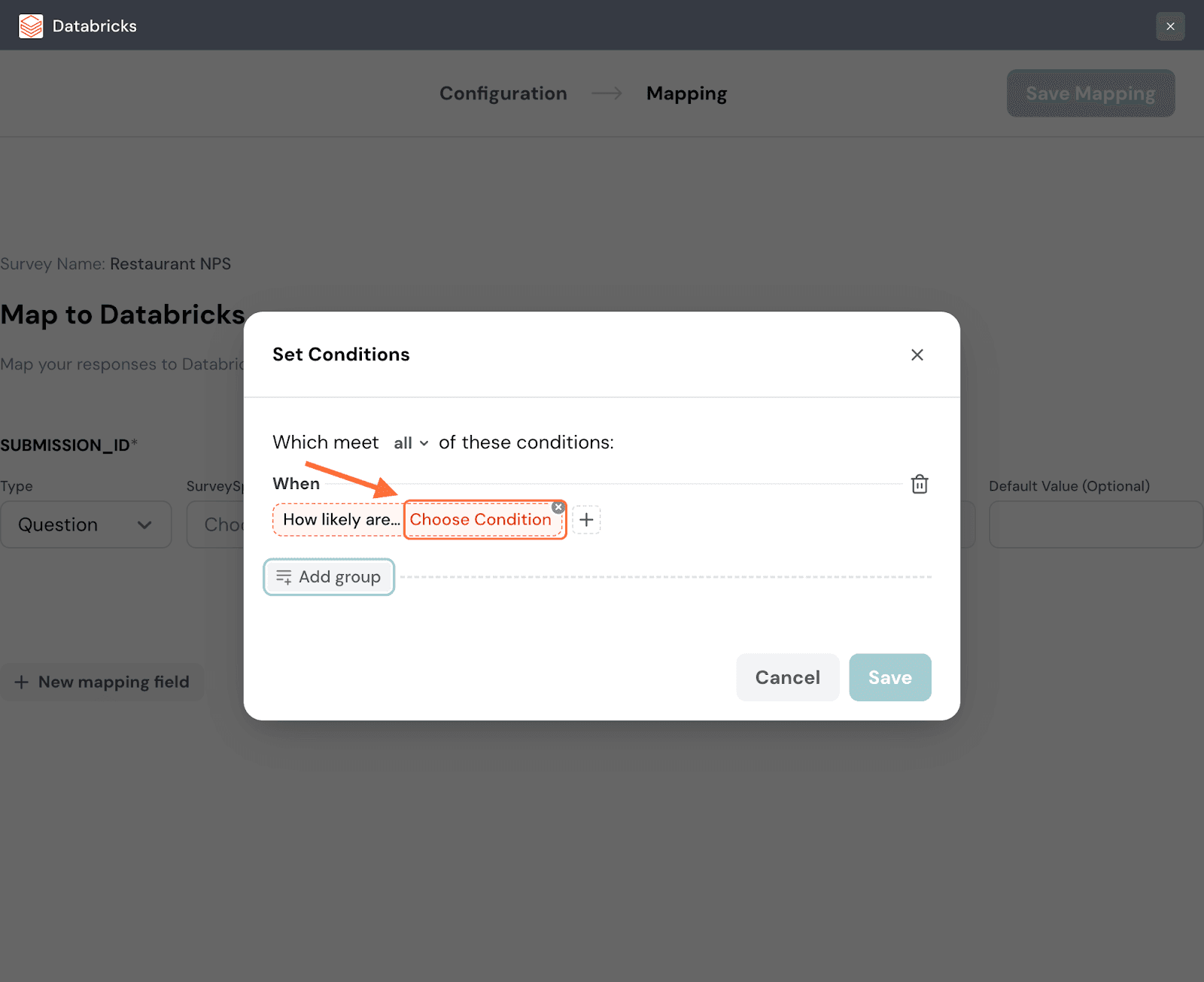
17. A list of comparison operators appears, choose one.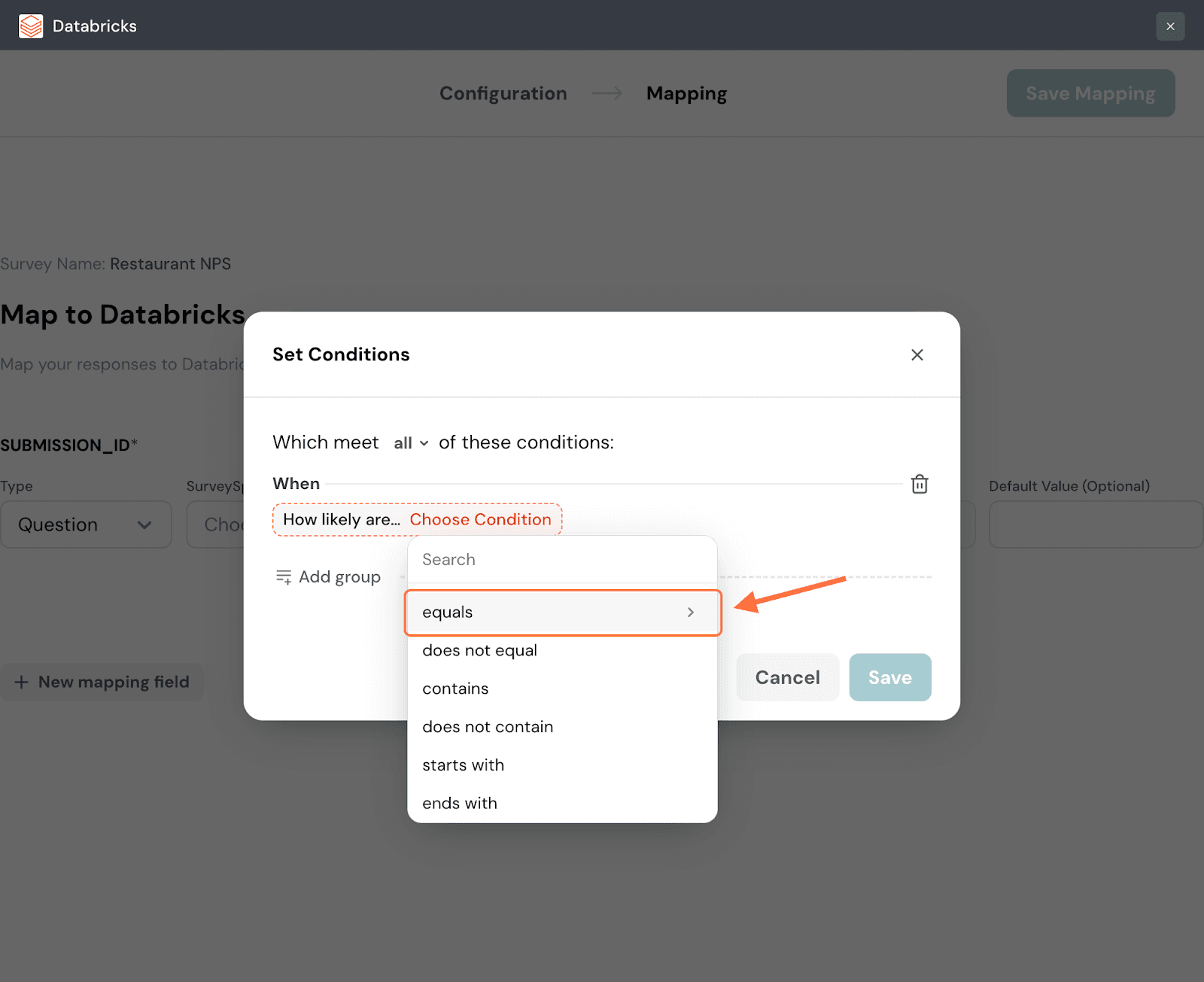
18. Input a value for the data to be tested against and then click Apply.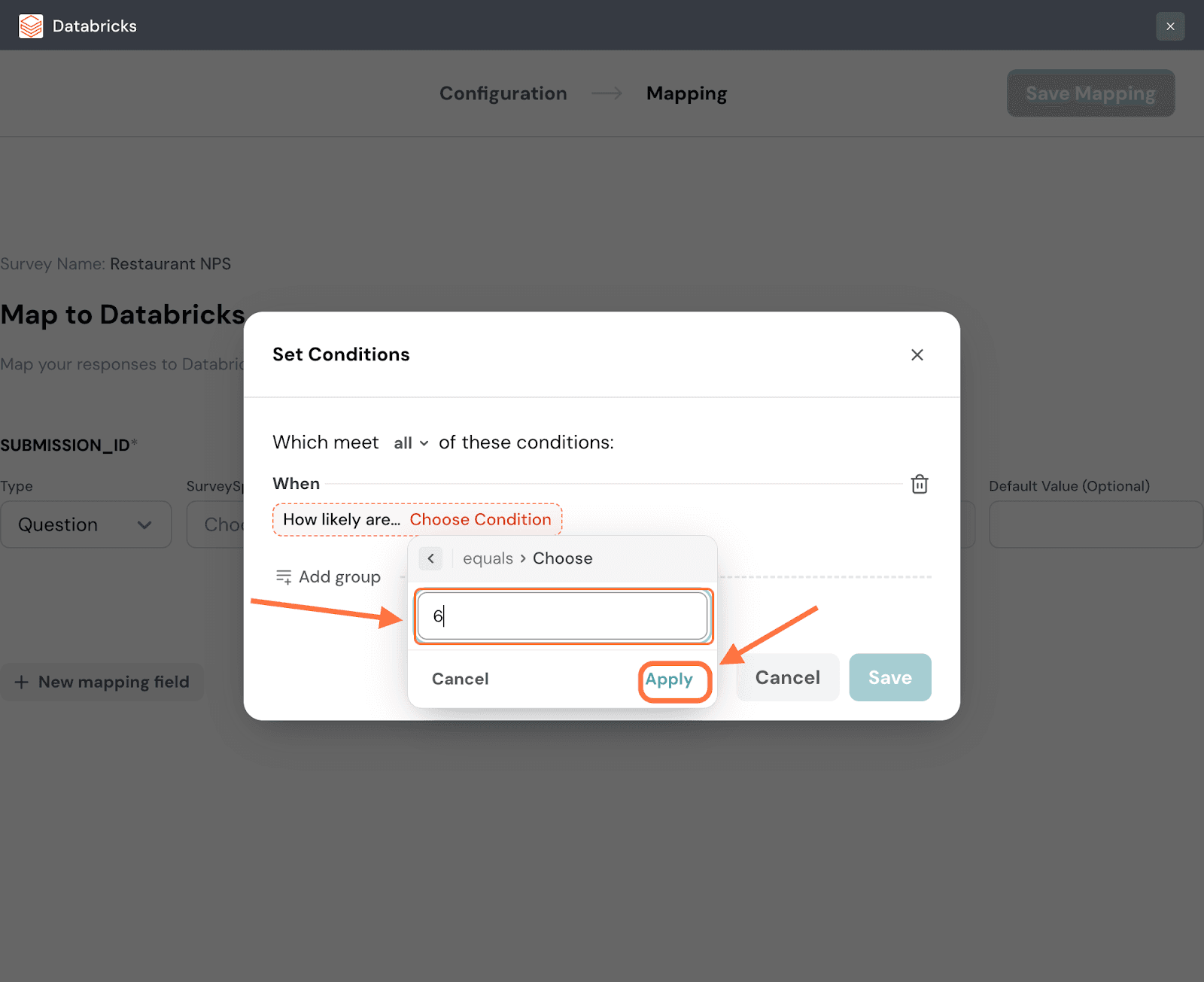
19. You can turn a condition into a group of conditions by hovering near it and then clicking on the plus icon that appears to the right. Repeat the same steps as above to create another condition.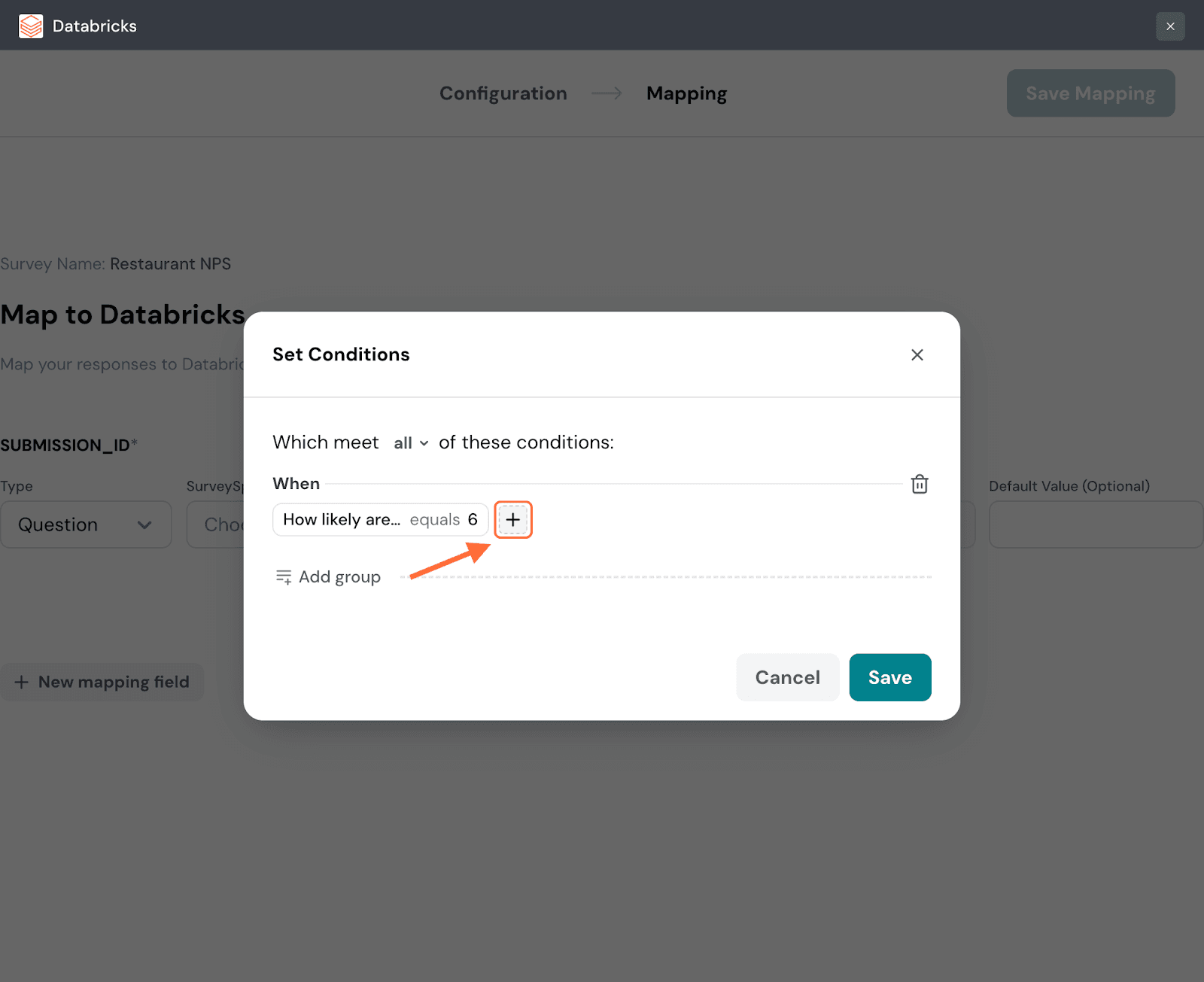
20. Within a group of conditions you can set conditional logic: and/or. The default is and, but if you’d like to change it, click on the drop-down.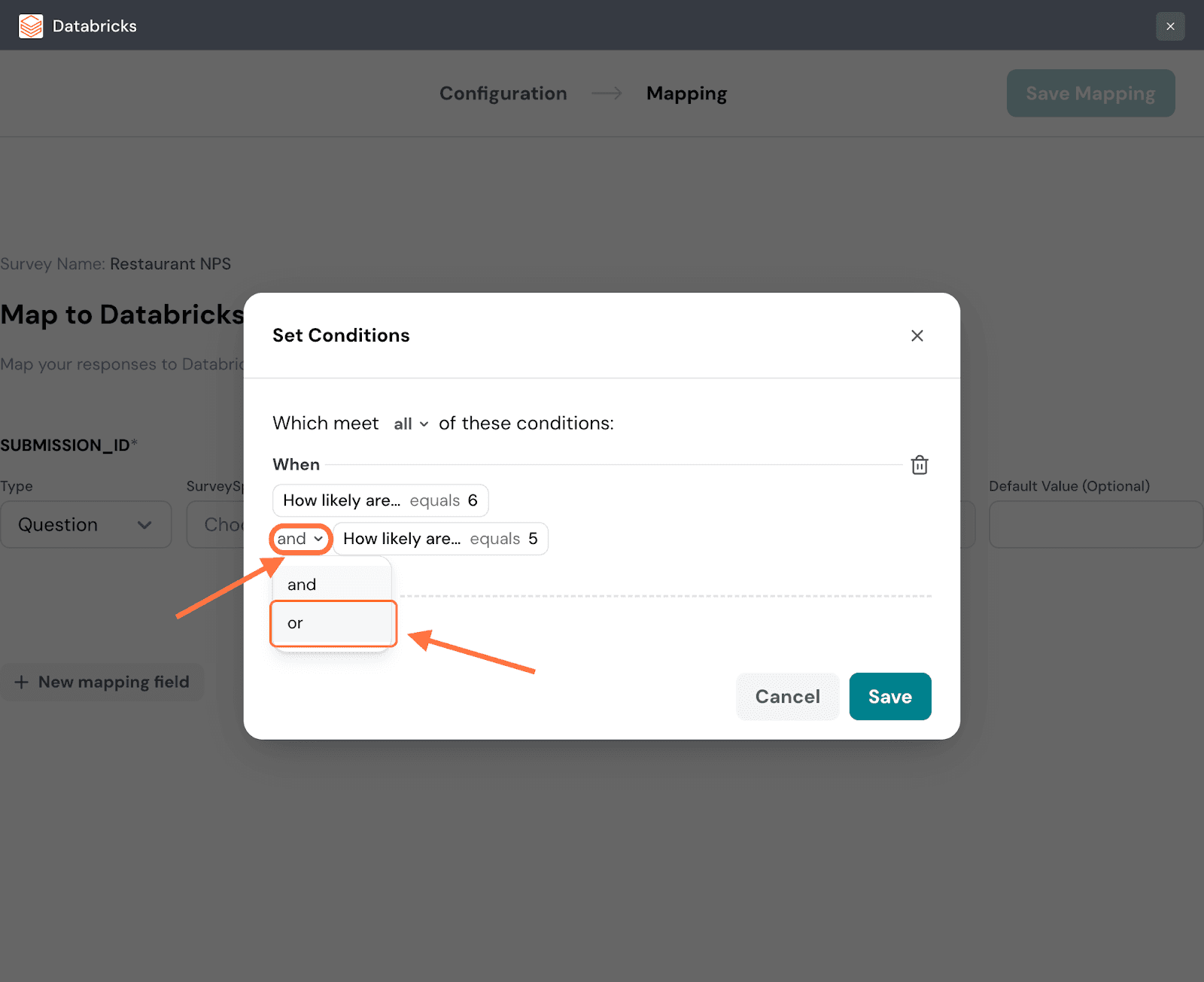
21. Click on Add Group to add more conditions/condition groups. When you’re done, click Save.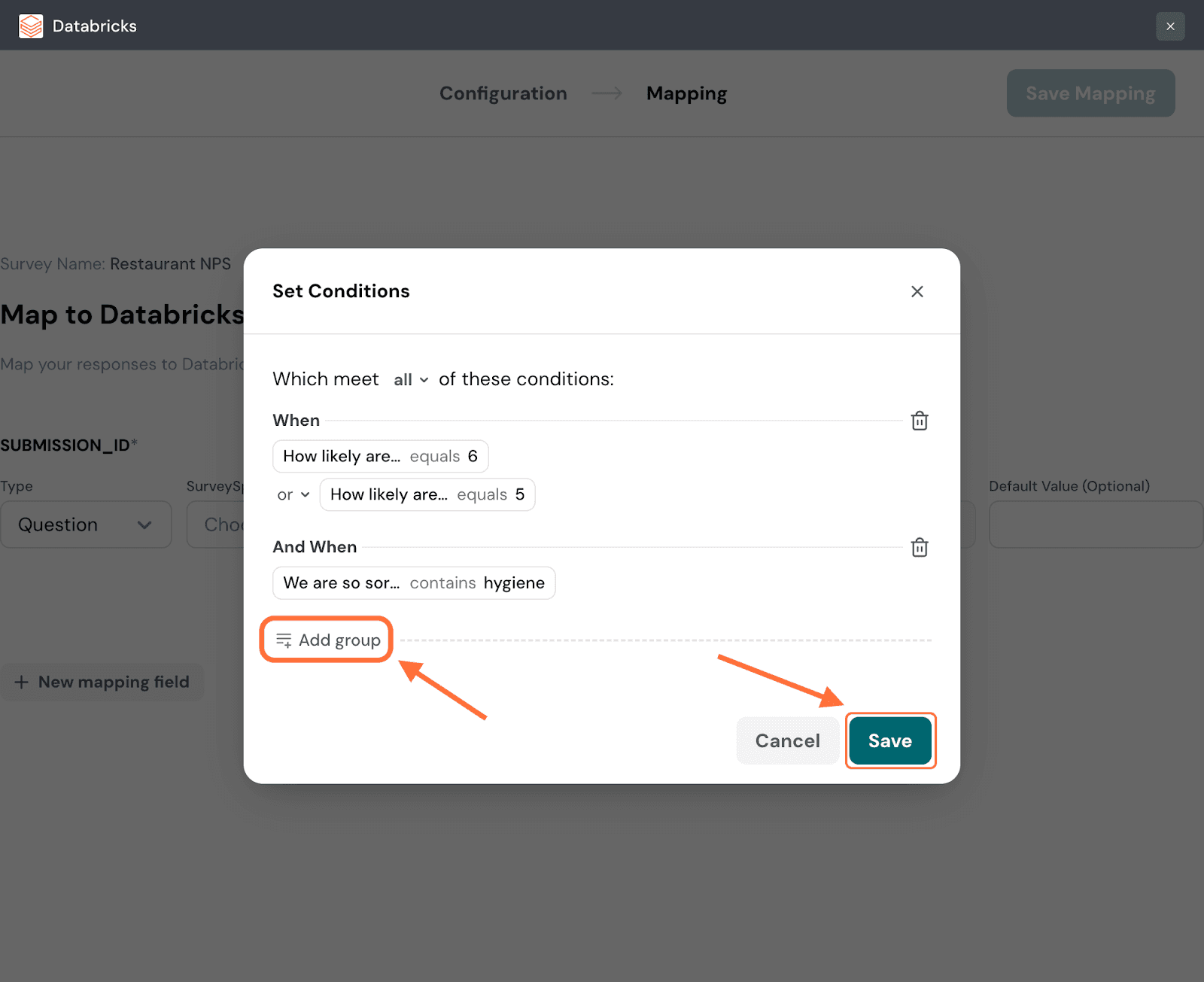
22. The first step of creating a mapping is to first map a response property to the SUBMISSION_ID field in Databricks. This is mandatory. The default property type is a question, but you can change it by clicking on the drop-down and choosing from the options.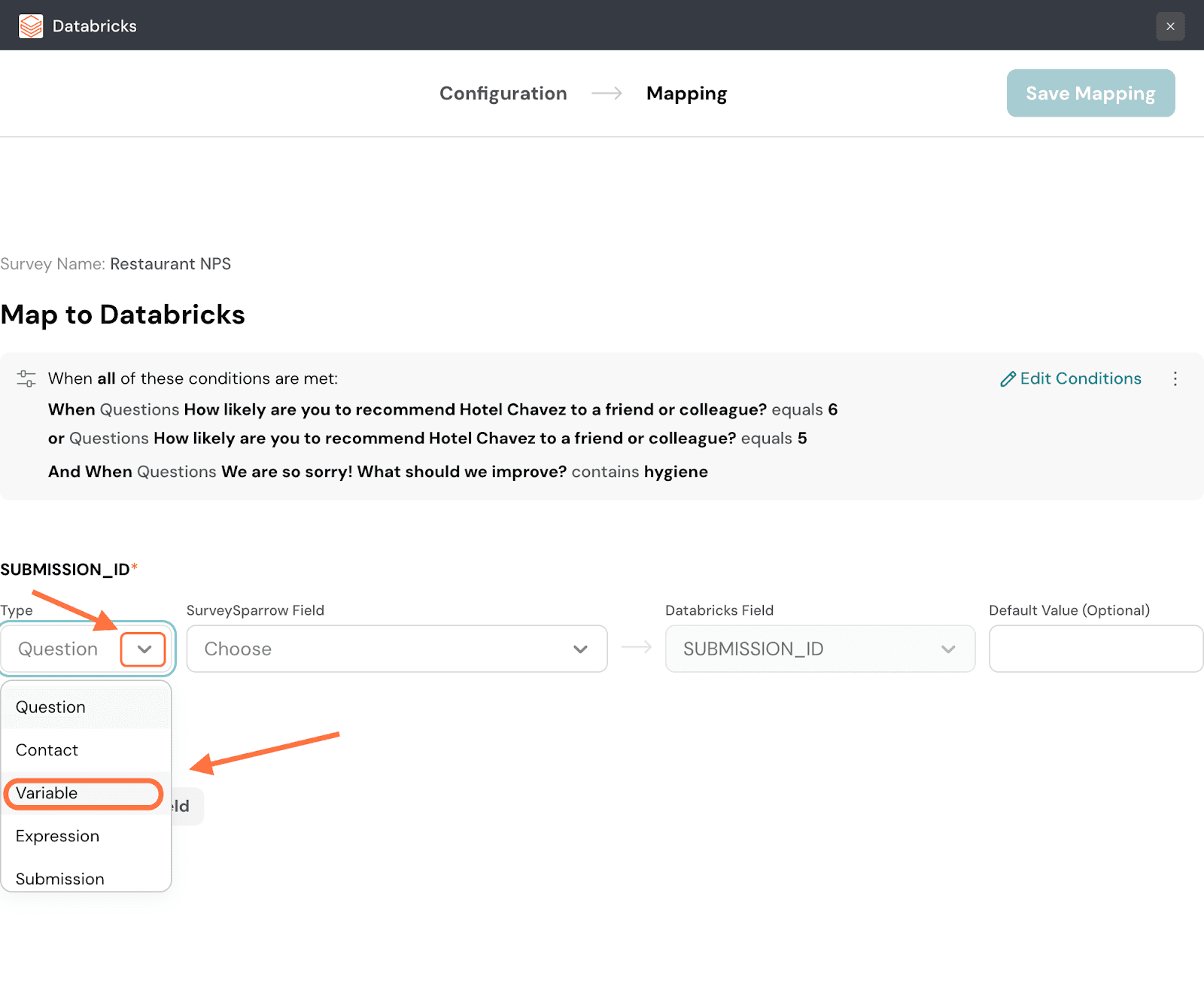
23. Next, you must choose a particular item of that property type that you’ve already created for the survey. Click on the drop-down menu under SurveySparrow Field and choose from the options.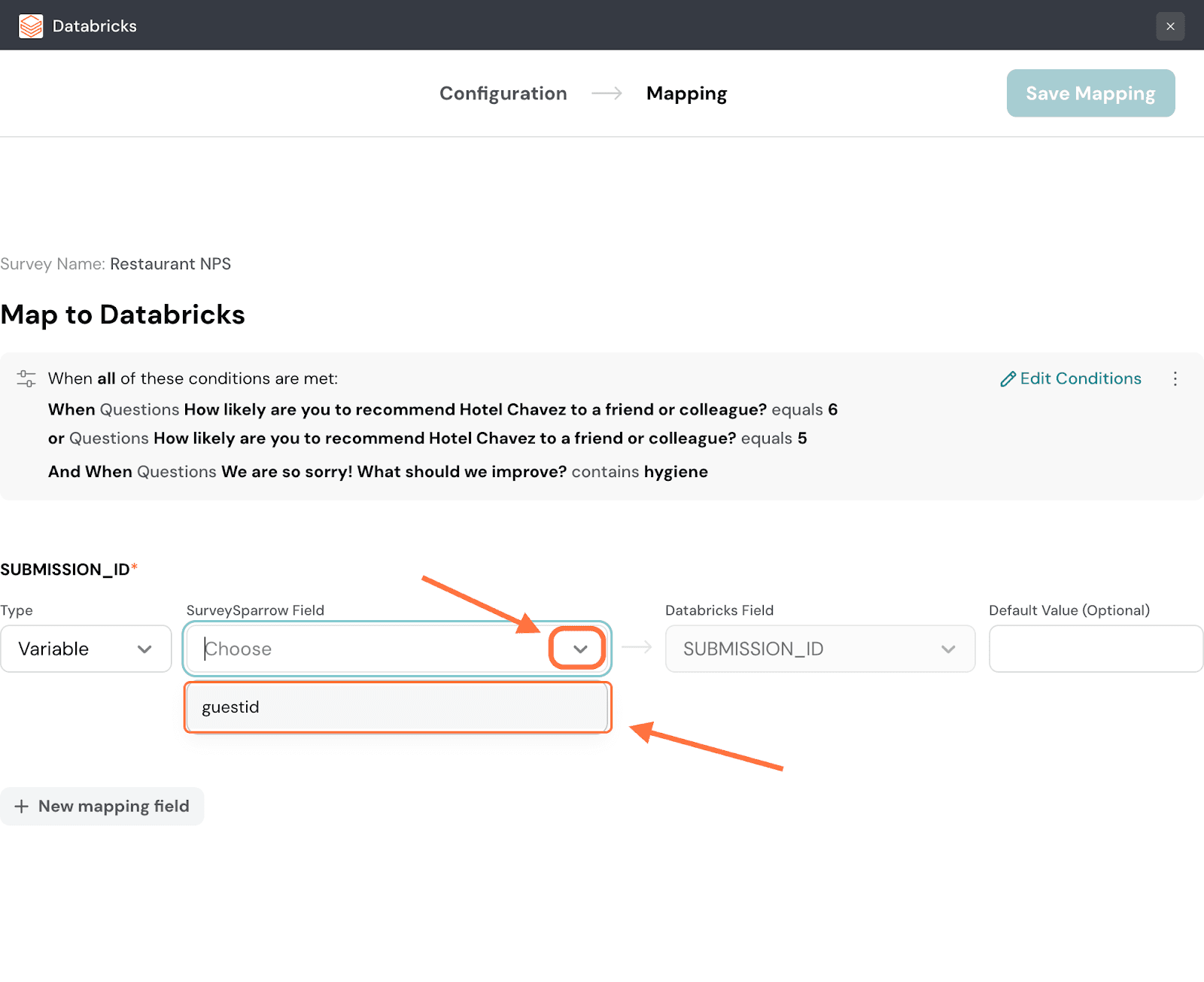
24. If a particular response has no data for the chosen property, the Databricks field will remain empty. But you can choose to fill in a default value that will be filled in as a substitute for such situations.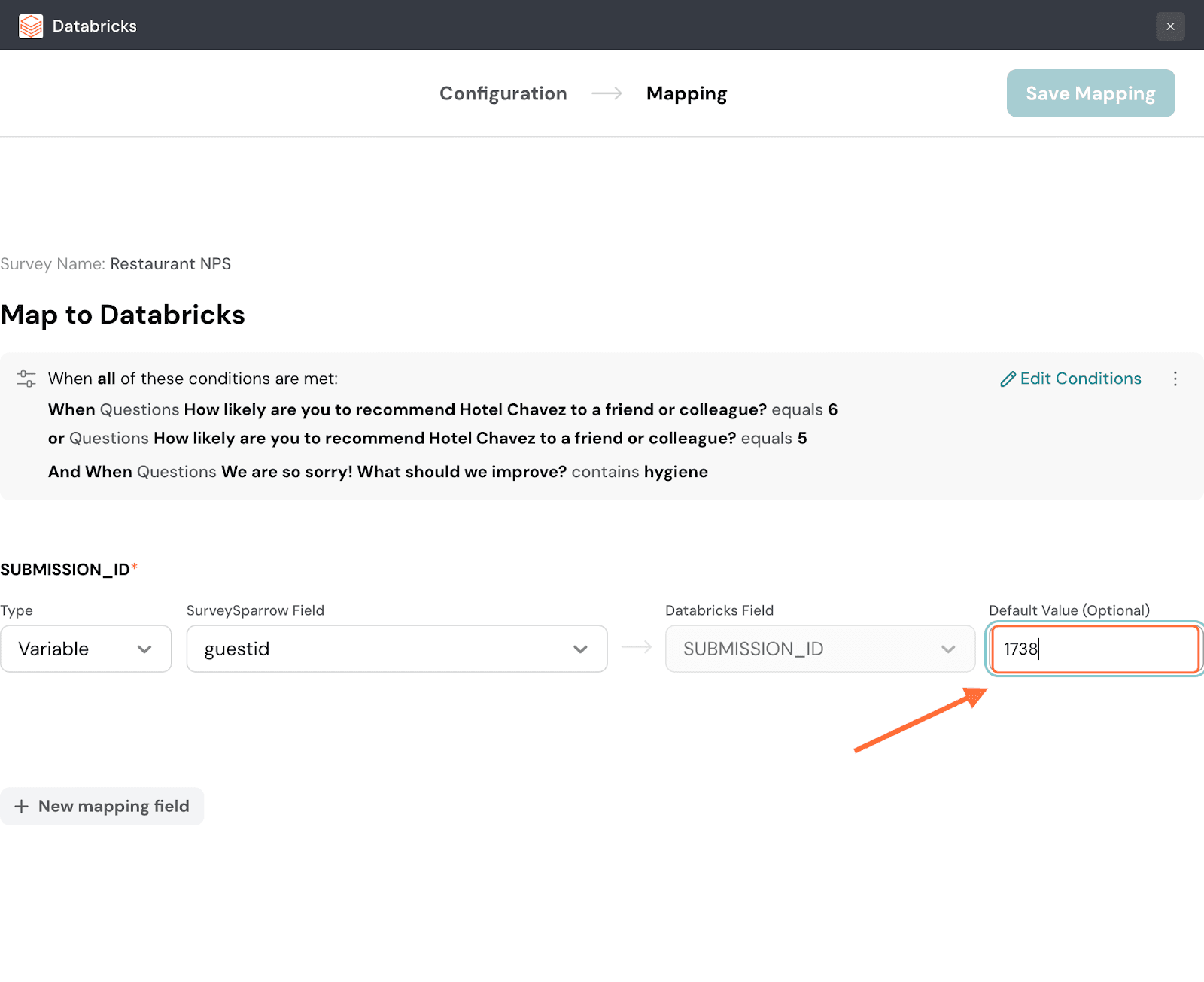
25. To add more mapping fields, click on New mapping field.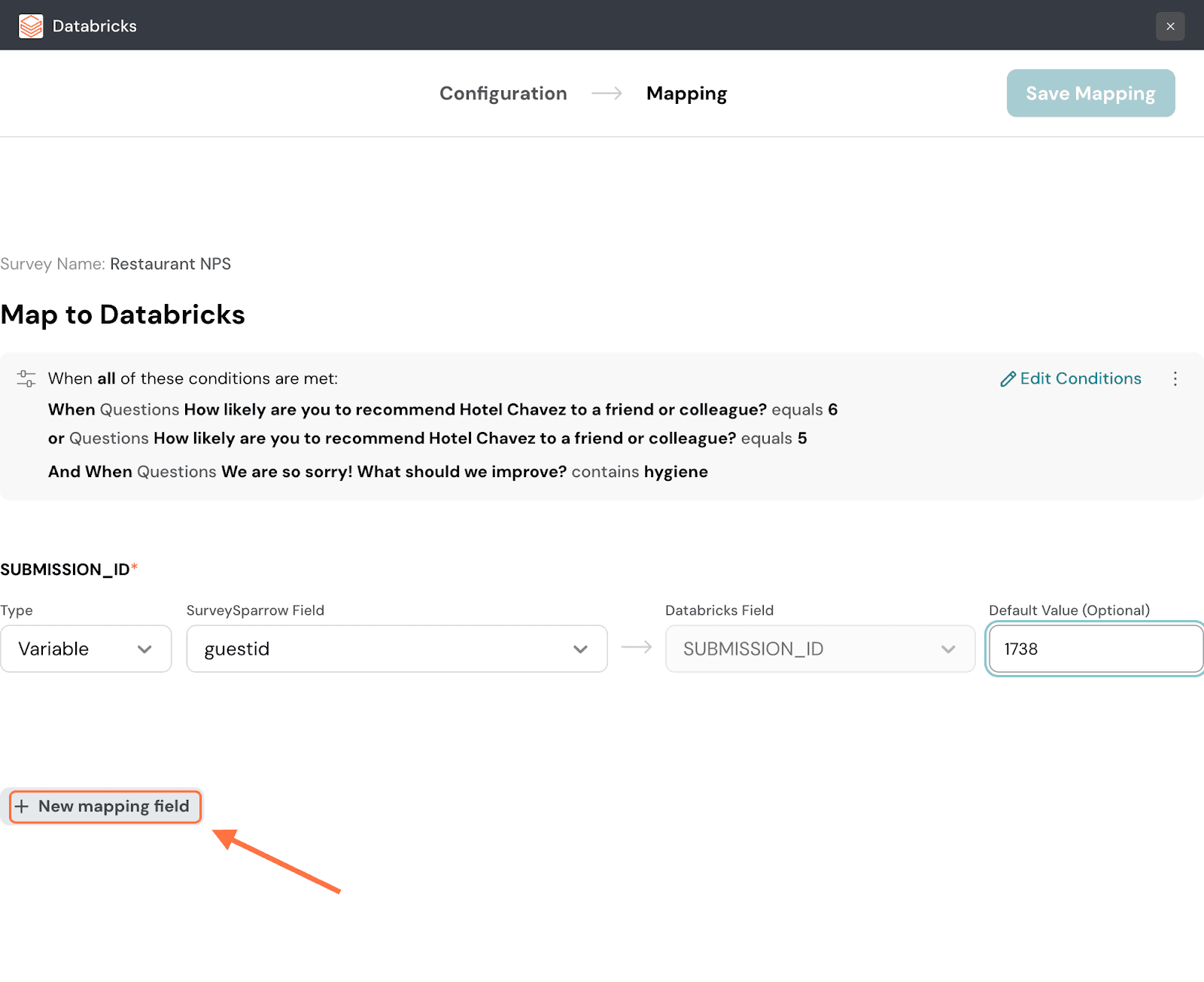
26. When you’re done, click on Save Mapping.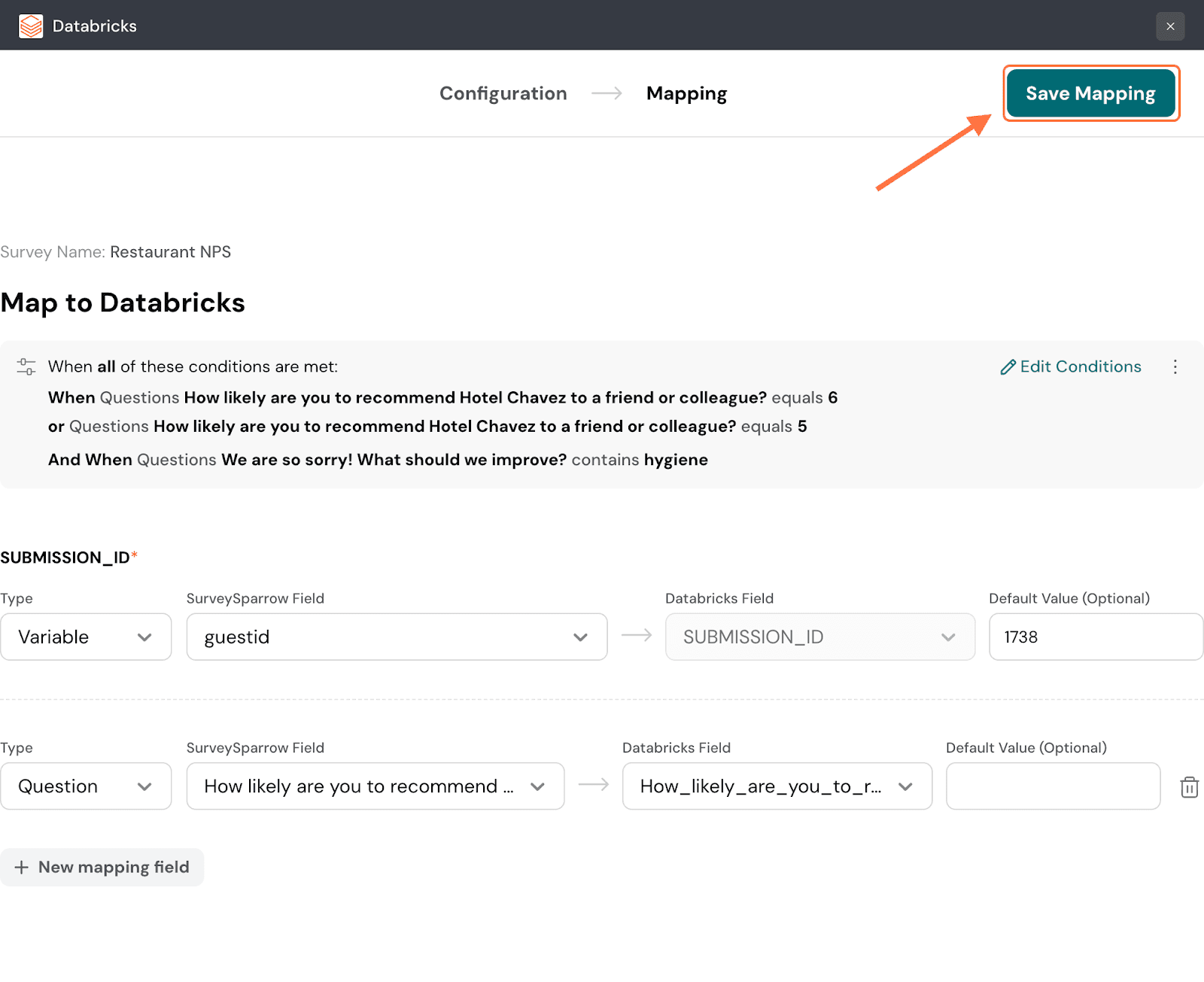
27. Create a name for the mapping, then click on Save Mapping.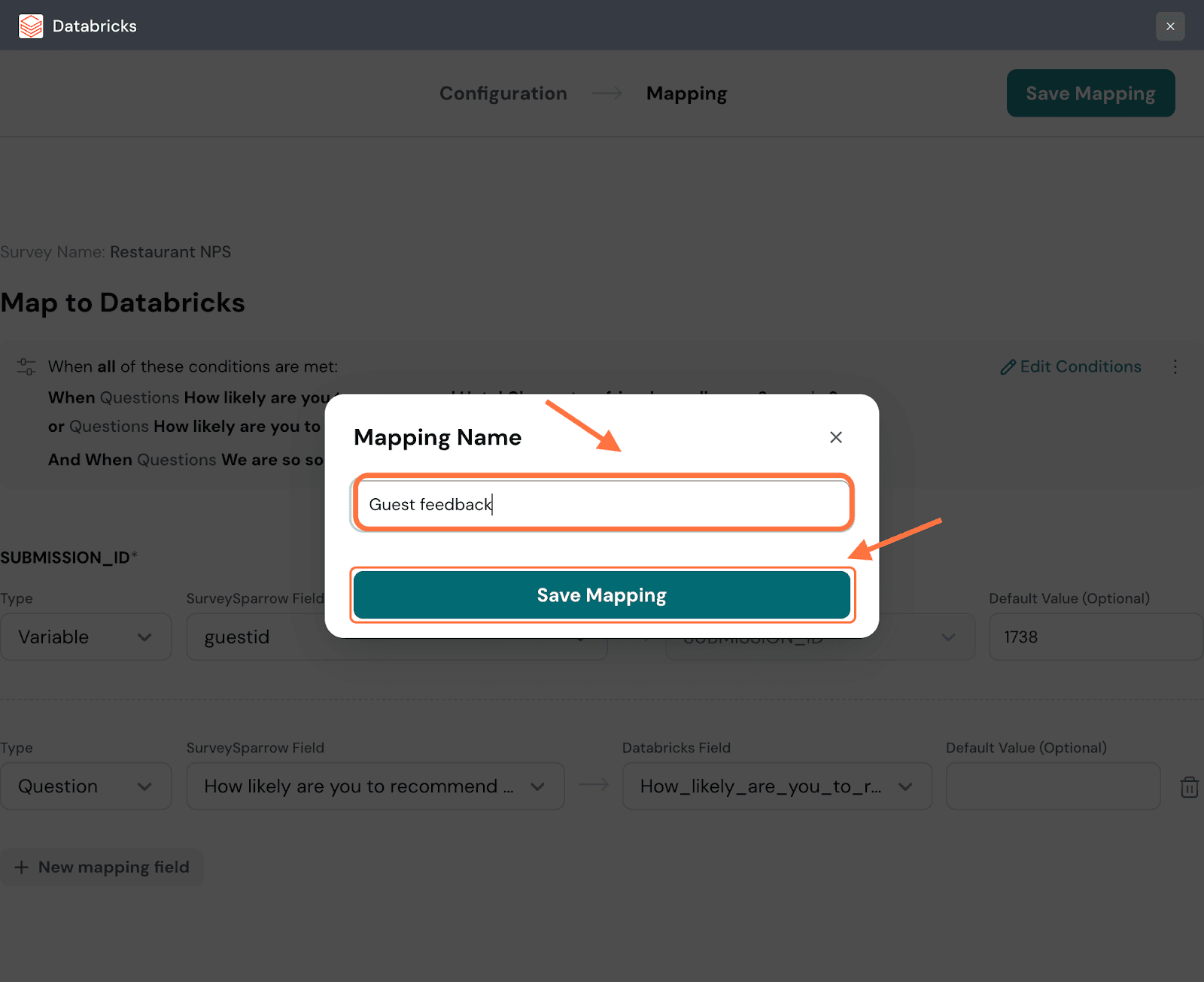
28. After the mapping is saved, you’ll be taken to a screen where you can access all saved mappings. To review the mapping configuration, click on the mapping.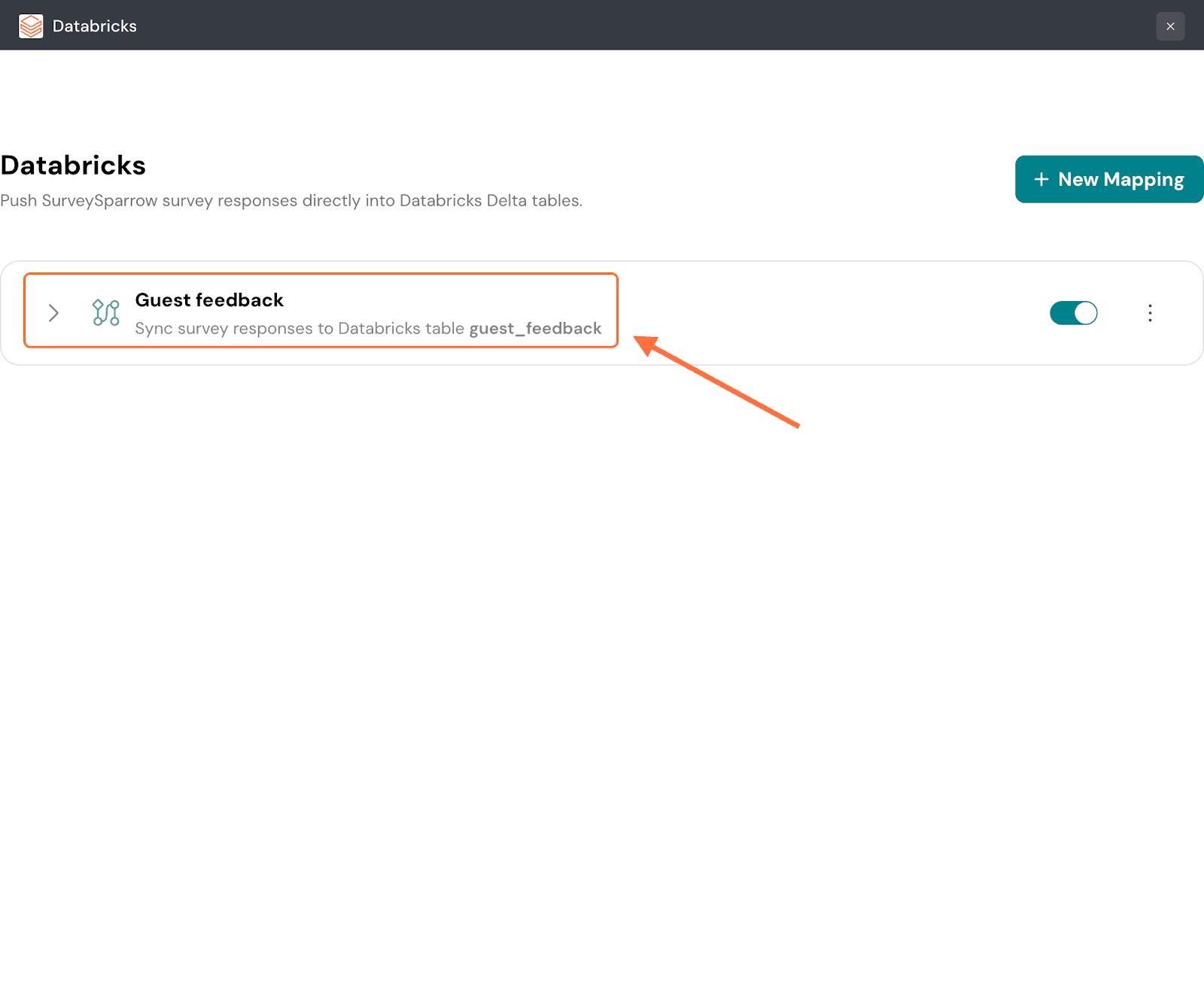
29. The mapping tab expands to show you its settings. If you’d like to modify it, click on the ‘Edit….’ button.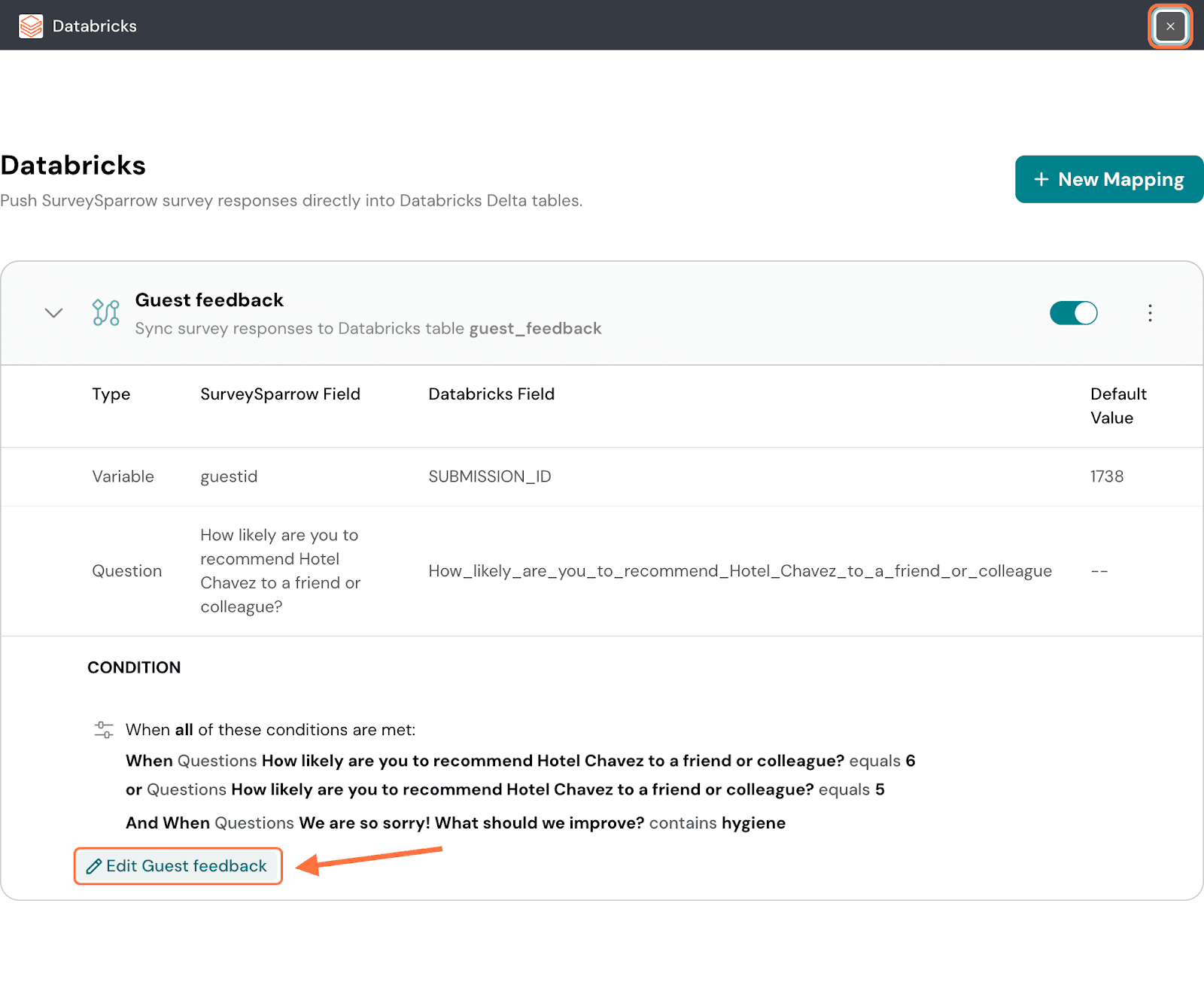
30. To pause the mapping, click on the green toggle button.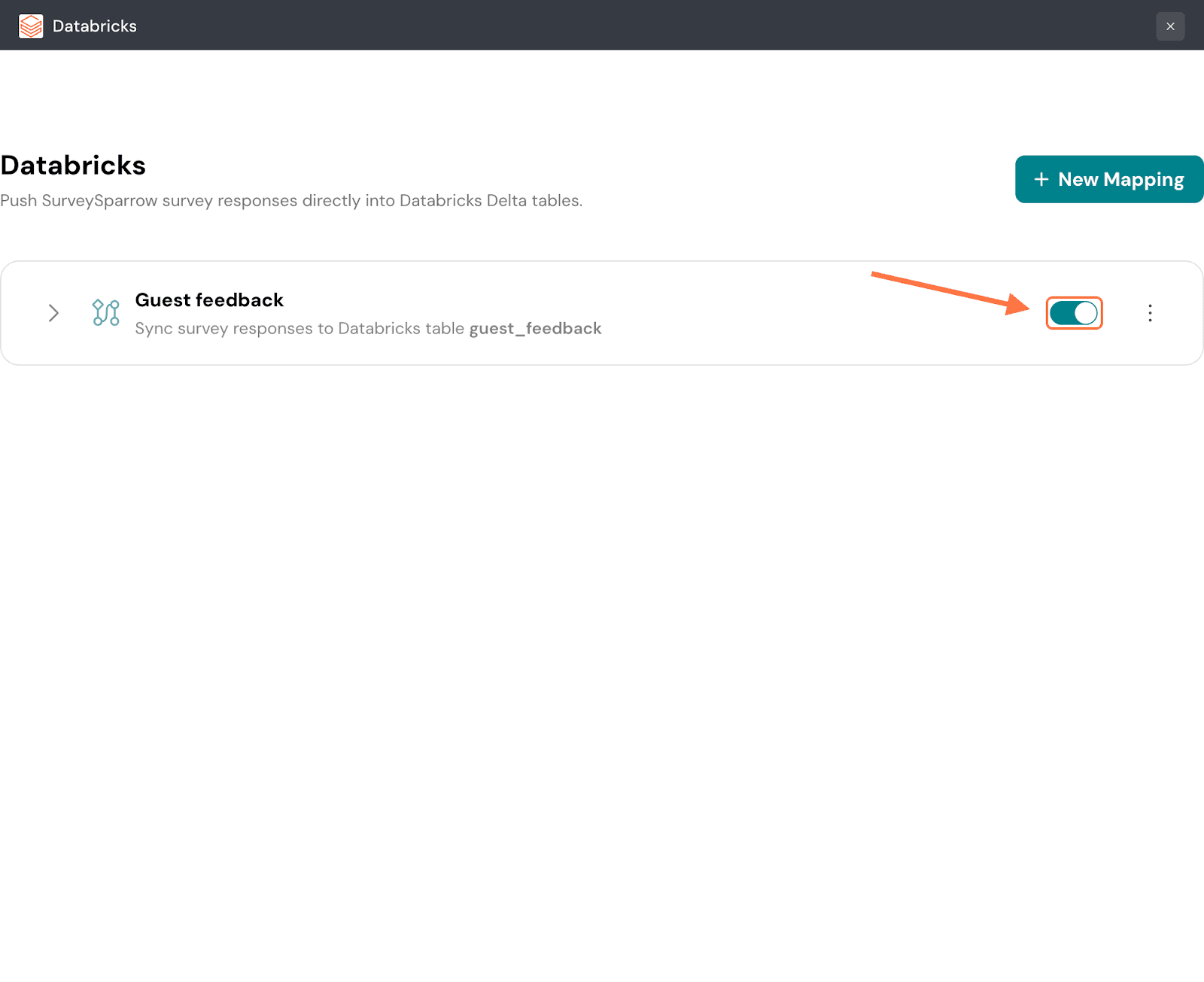
Note: Any responses that come in while the mapping is paused will not be synced to Databricks later.
31. To delete the mapping, click on the vertical three-dot icon, then click on Delete.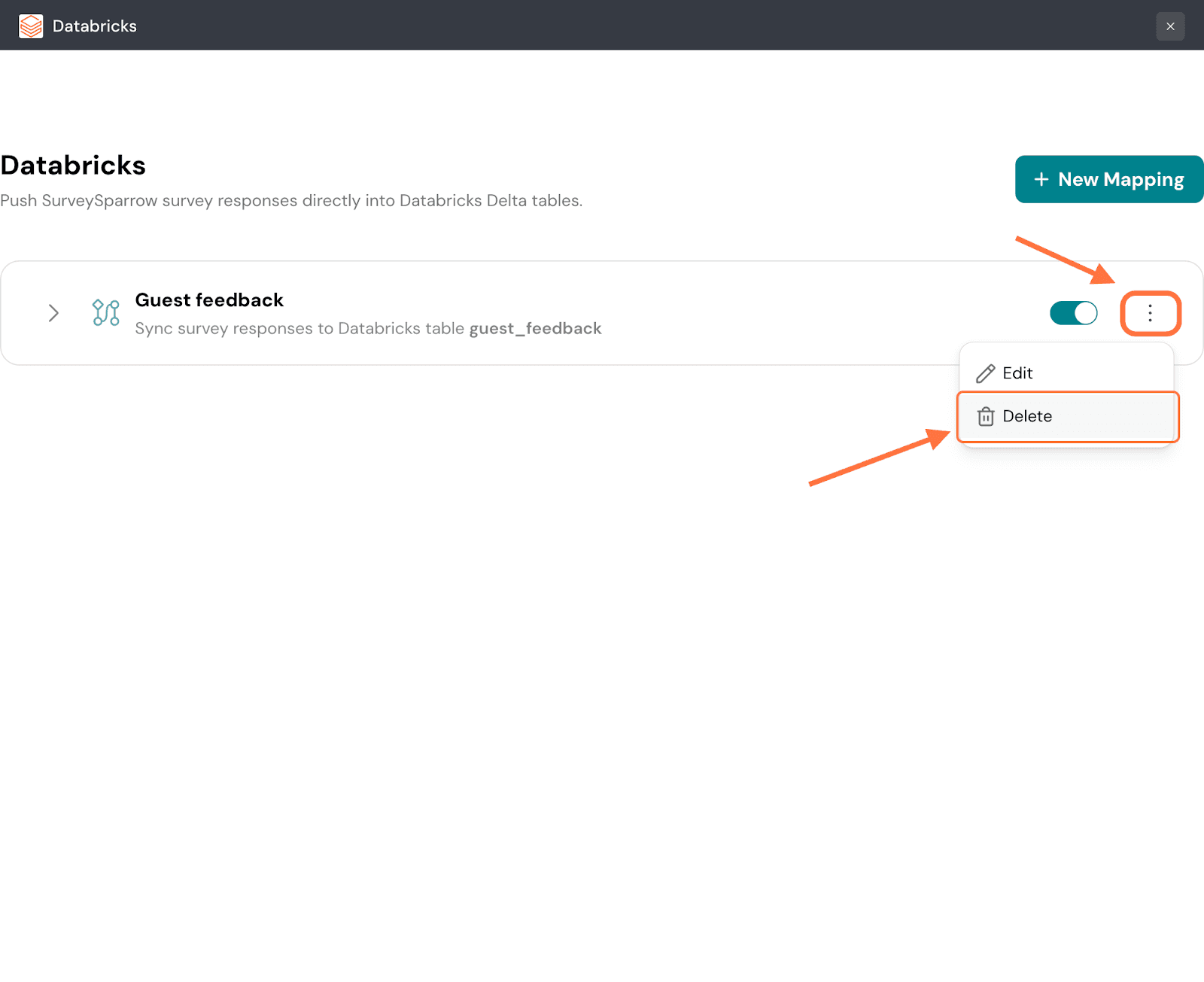
32. Click on Confirm to proceed.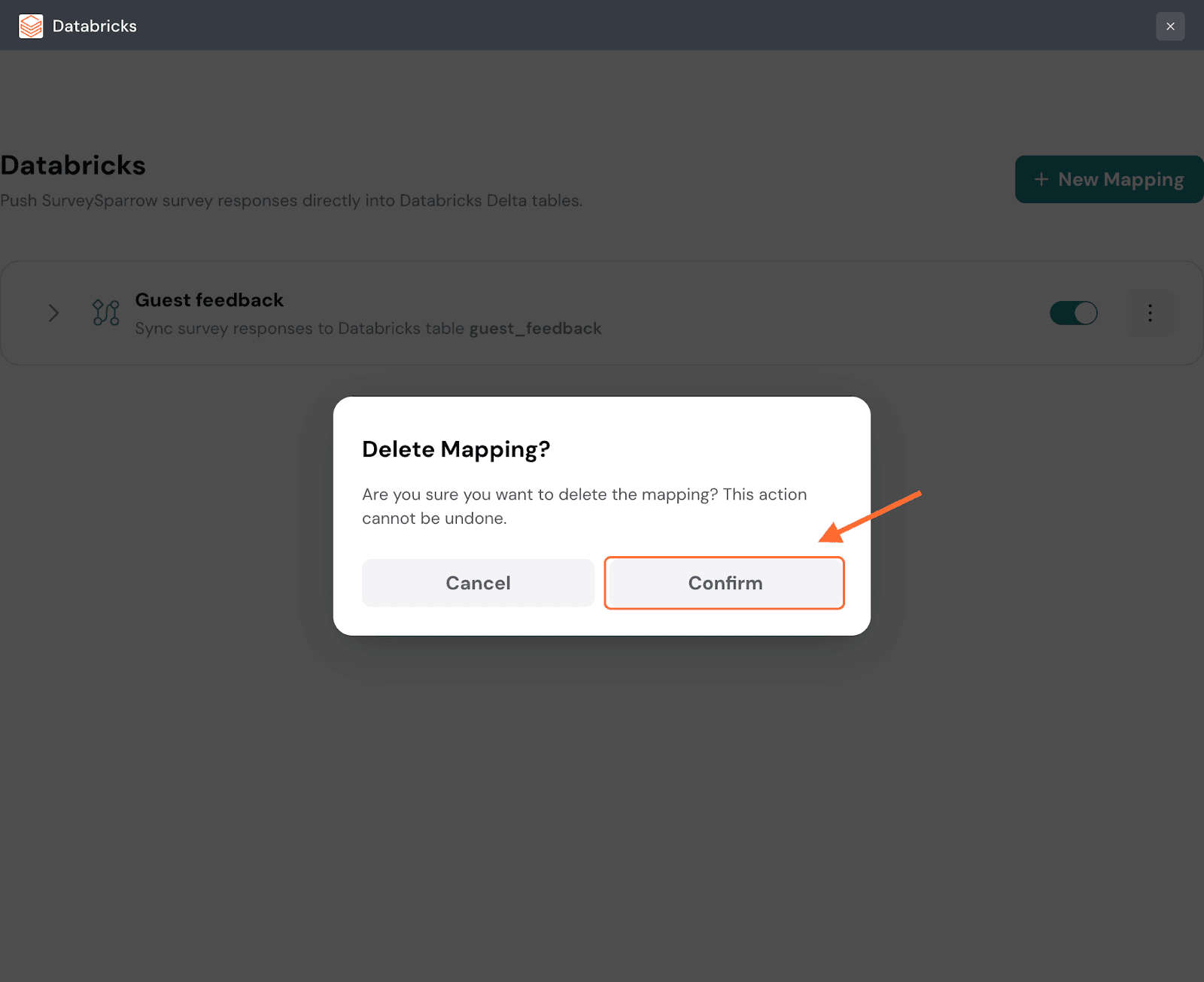
33. Click on New Mapping to add another mapping.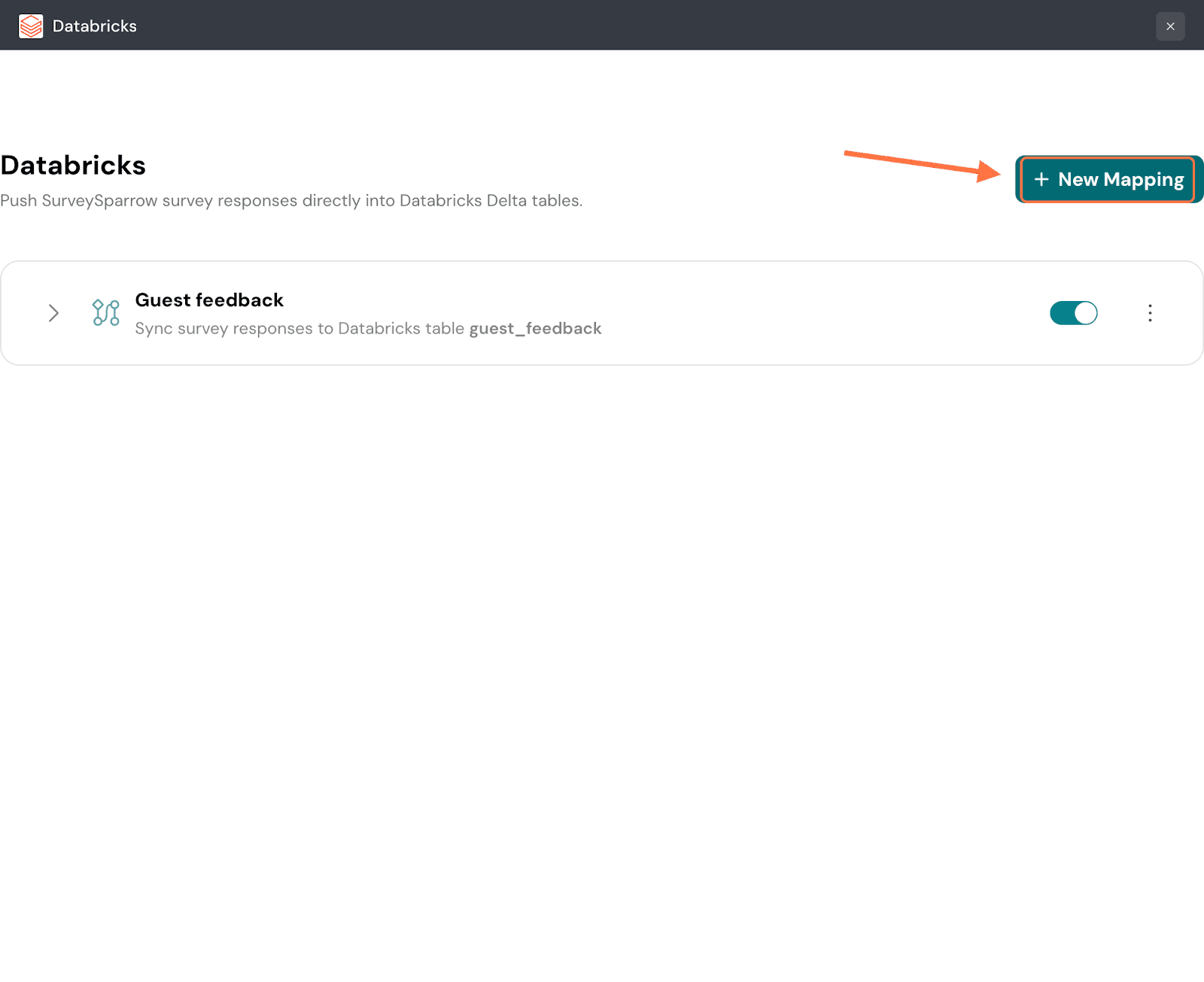
34. Now let’s explore the other set of steps to create a new table for mappings. Once you’re selected Create New Table as your action, enter a table name and click on Continue Mapping.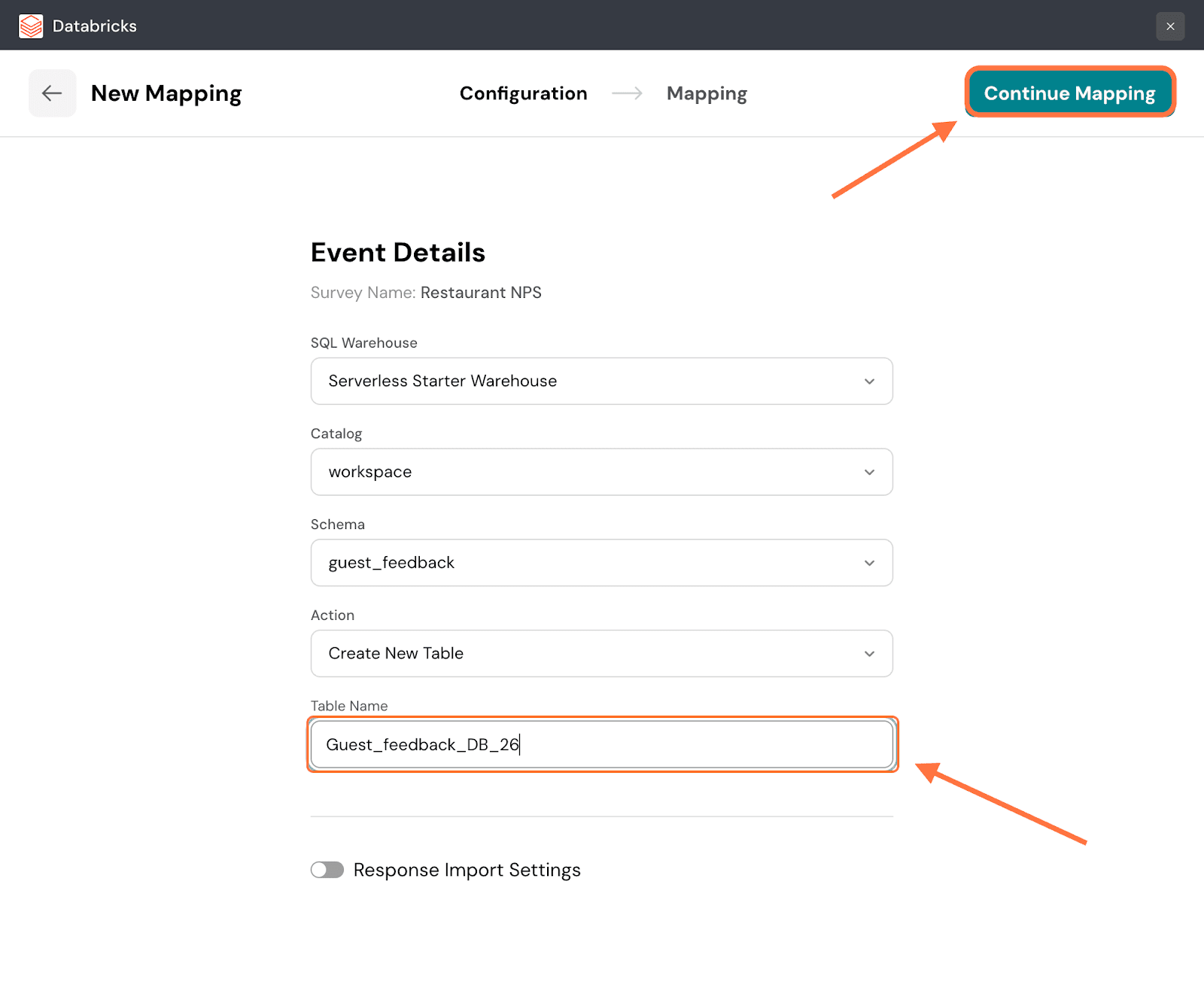
Note: The table names cannot have a space/period/colon/slash, else the mapping will not proceed.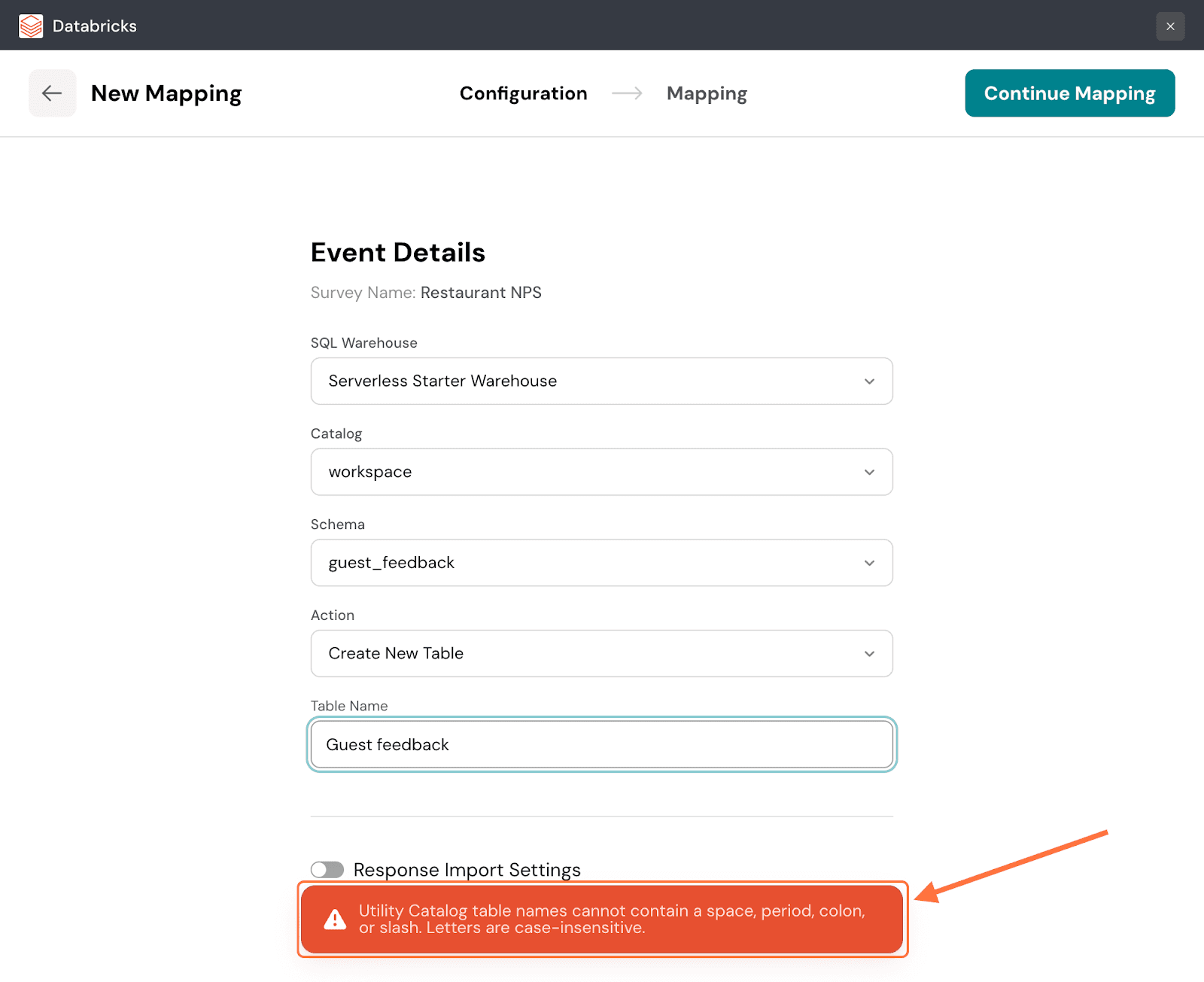
35. In the mapping section, the default option is to send all the response data. You can see all the response properties and their quantities. But if you want to be selective, click the button next to Send Selected data.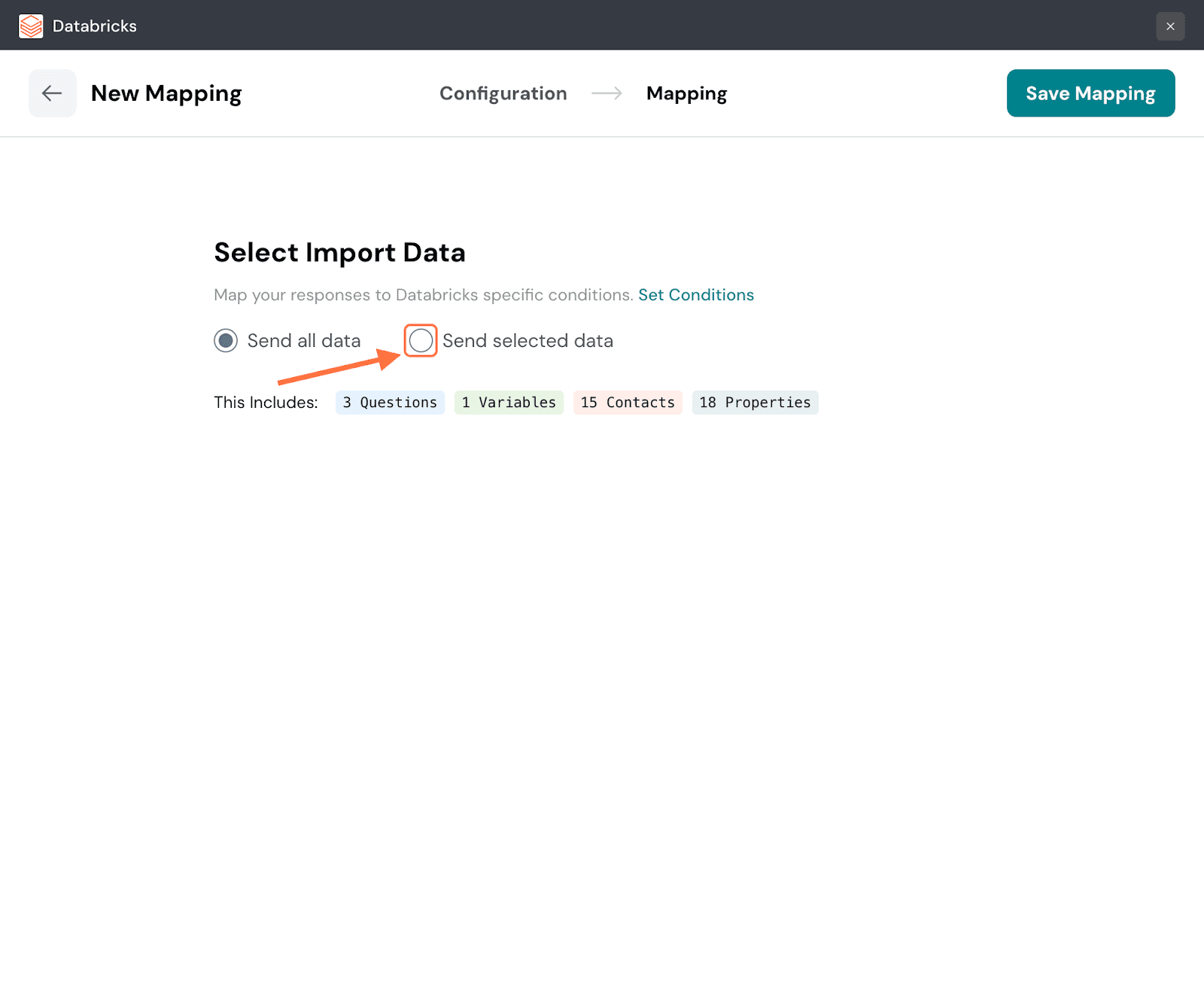
36. You will be shown a series of tabs for each response property. Each tab will have a list of items for that particular property. Click on the checkboxes of the items you want to import to Databricks. Navigate through the respective tabs and select the ones you want. You can also use the search box to find items.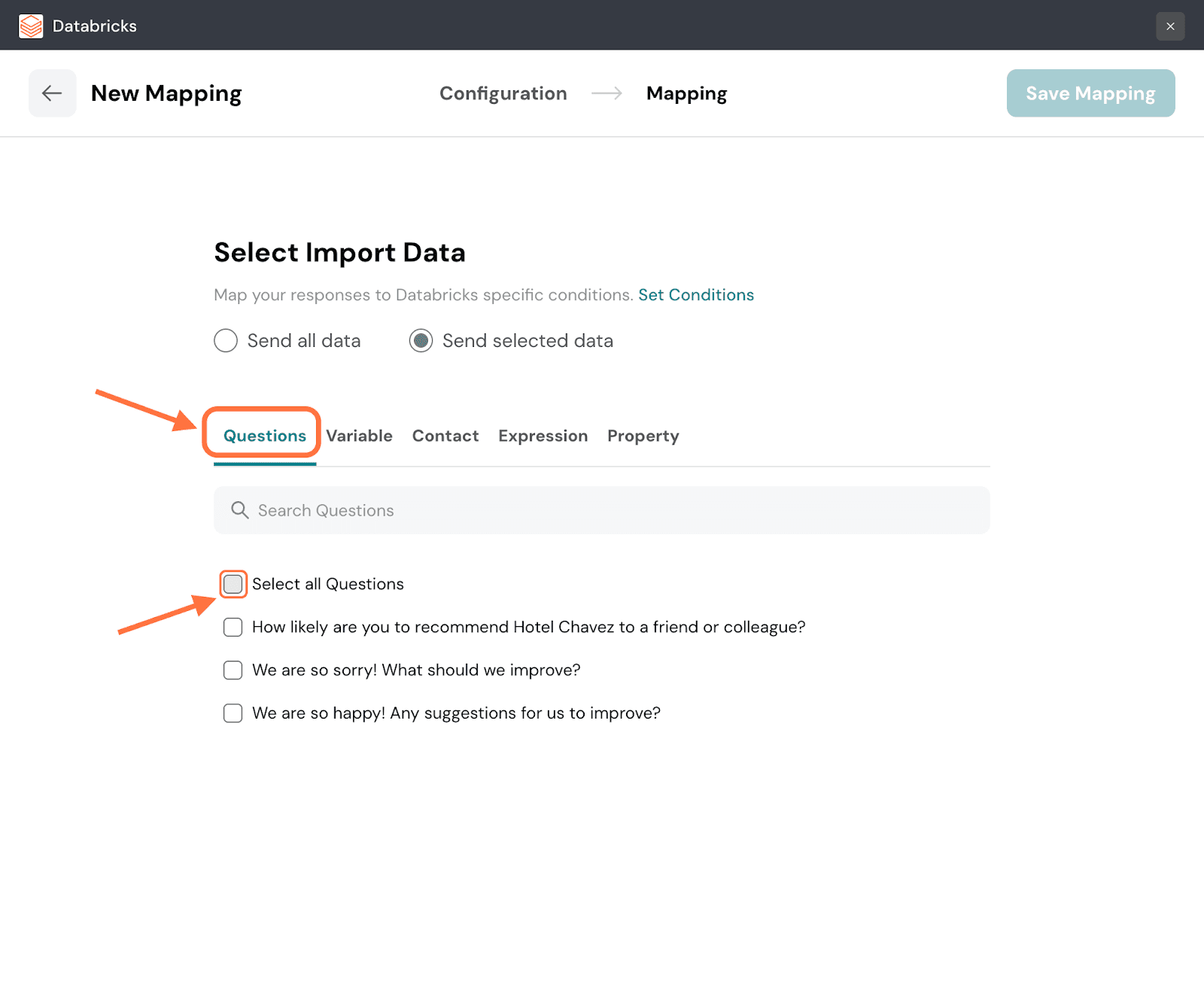
37. When you’re done, click on Save Mapping.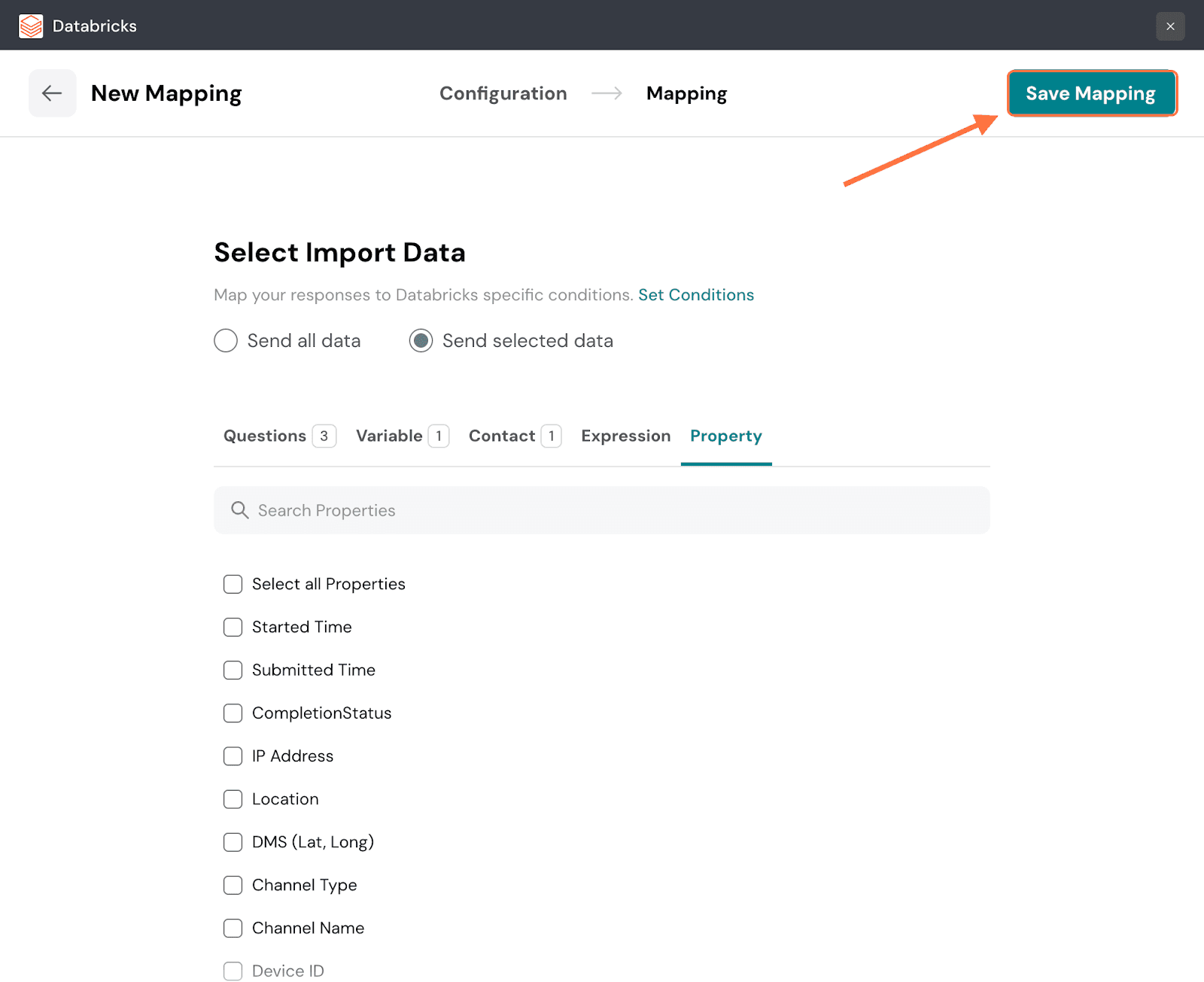
38. Create a name for the mapping and click on Save Mapping.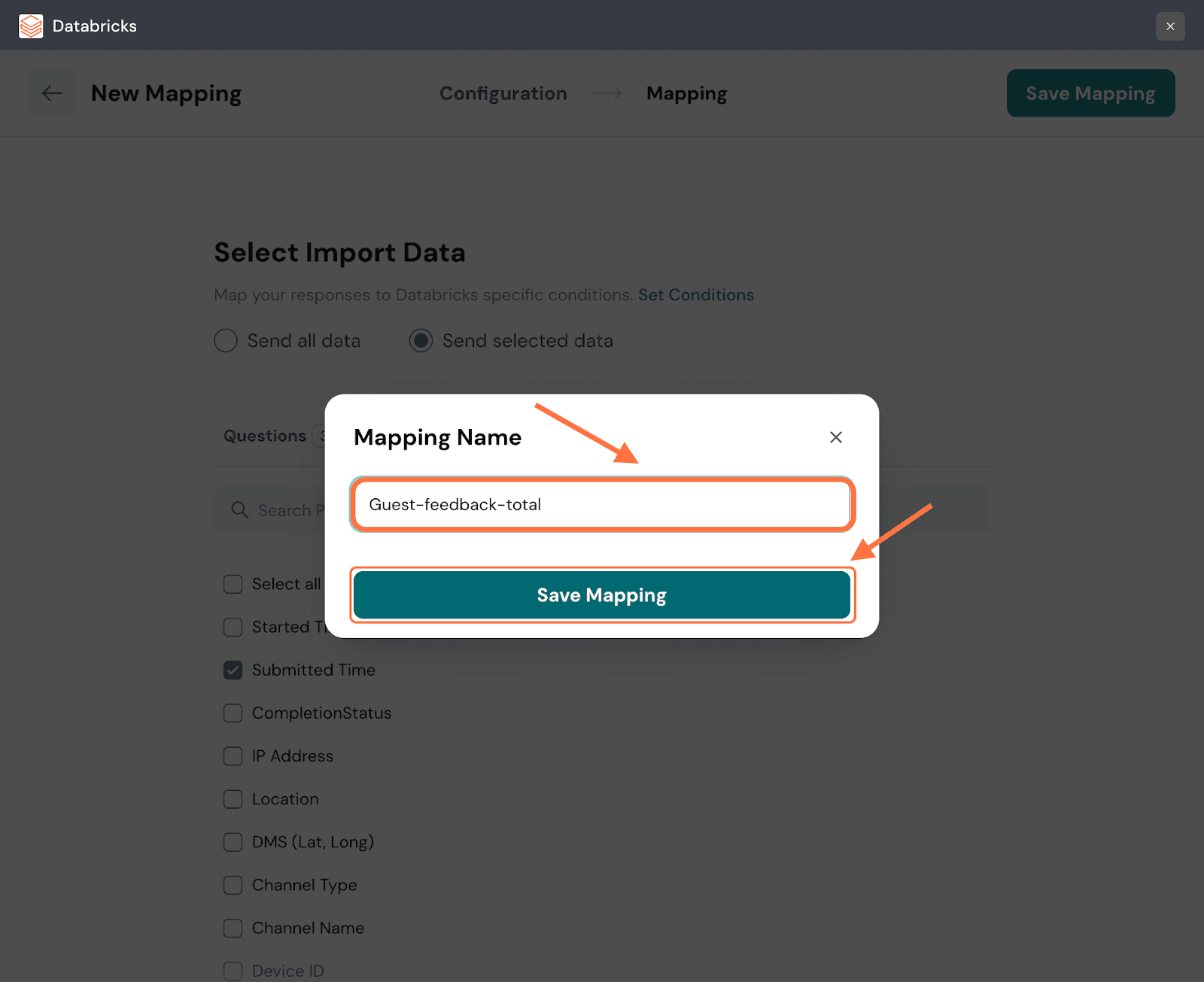
Now, you’re ready to make SurveySparrow and Databricks work together seamlessly. Your survey responses will now land automatically in your warehouse — ready for analysis, modeling, or dashboards.
Go create your first mapping and turn raw feedback into one of your most valuable data assets. Feel free to reach out to our community, if you have any questions!
Powered By SparrowDesk